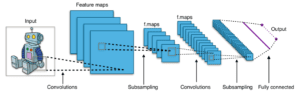
Ils renouvellent considérablement l’intérêt pour l’intelligence artificielle et le deep learning. Les travaux sur des réseaux convolutifs et algorithmes de rétropopagation, notamment de Yann LeCun (1998), donnent naissance à de nombreuses applications en reconnaissance d’images et vidéo, pour les systèmes..Lire la suite
Ce concours de reconnaissance visuelle d’objet par intelligence artificielle devient une référence. Le challenge de reconnaissance visuelle à grande échelle d’ImageNet (ILSVCR) est un concours annuel de reconnaissance d’objet. Organisé par l’Université Stanford, l’Université Carnegie-Mellon, l’Université du Michigan et l’Université..Lire la suite
Ce problème est l’un des plus étudiés en mathématiques, statistiques et machine learning grâce au challenge Netflix. Pour améliorer son moteur de recommandation, la société Netflix met à contribution la communauté scientifique en organisant une compétition mettant en jeu un..Lire la suite
Des réseaux neuronaux multicouches incluant une étape automatique d’apprentissage de la représentation des données. Geoffrey Hinton, Simon Osindero et Yee-Whye Teh optimisent le fonctionnement des réseaux neuronaux multicouches (A Fast Learning Algorithm For Deep Belief Nets). Le concept du deep..Lire la suite
Puissant, ce modèle de machine learning est très utilisé aujourd’hui. Méthode dite d’ensemble, cousine du boosting, les forêts d’arbres décisionnels (ou forêts aléatoires de l’anglais random forest classifier) ont été formellement proposées en 2001 par Leo Breiman et Adèle Cutler...Lire la suite
Quelques chercheurs dont LeCun et Bengio poursuivent leurs recherches dans cette voie malgré les critiques. Yann LeCun, Yoshua Bengio et d’autres publient des articles sur l’application des réseaux neuronaux à la reconnaissance de l’écriture manuscrite et sur l’optimisation de la..Lire la suite
Tibshirani propose une méthode de régression pour permettre aux approches statistiques linéaires de faire face au « fléau de la dimension ». Lorsque le nombre de variables grandit si vite que les données deviennent éparses et éloignées, de nombreux algorithmes..Lire la suite
Une technique pour améliorer un algorithme, le « booster » par la démultiplication des règles de décision produites et par leur combinaison. Yoav Freund et Robert Schapire introduisent Adaboost (ou Adaptive boosting), l’une des premières méthodes pleinement fonctionnelles permettant de mettre en..Lire la suite
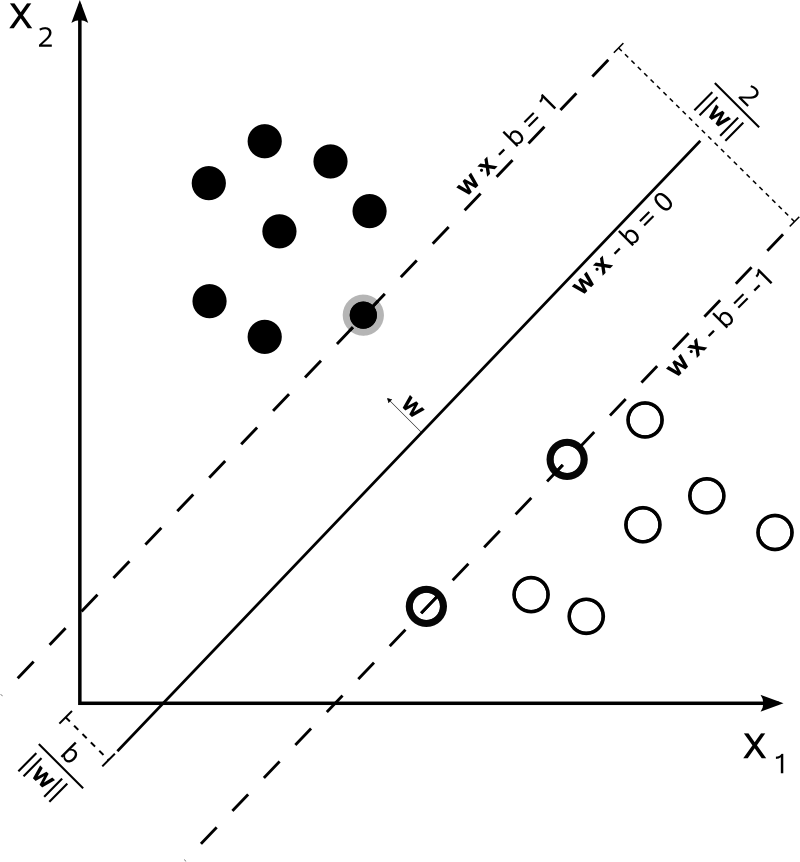
Cet ensemble de techniques d’apprentissage supervisé résout des problèmes de discrimination et de régression. Développés à partir des considérations de Vladimir Vapnik sur une théorie statistique de l’apprentissage (théorie de Vapnik-Chervonenkis), les machines à vecteurs de support ou séparateurs à..Lire la suite
Un changement de paradigme. Des membres du centre de recherches IBM TJ Watson publient « Une approche statistique de la traduction ». Ils annoncent le passage des méthodes de traduction automatique fondées sur des règles à celles fondées sur les probabilités...Lire la suite
TEAM
RÉDACTRICE EN CHEF : ISABELLE BELLIN – EXPERTISE : NICOLAS VAYATIS