La machine Libratus repousse encore un peu les limites de l’intelligence artificielle dans le jeu. Le poker résistait encore à l’intelligence des algorithmes. Mais l’intelligence artificielle développée par des chercheurs de Carnegie Mellon, au sein d’une équipe constituée autour de..Lire la suite
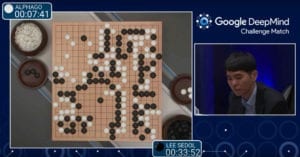
AlphaGo est le premier programme à battre sans handicap un des meilleurs joueurs mondiaux, Lee Sedol. Le système, développé par DeepMind (rachetée par Google en 2014), a initialement été entraîné pour « imiter » les joueurs humains, en retrouvant les..Lire la suite
Pour tirer profit du deep learning, Google a conçu et utilise des unités de traitement TPU (Tensor Processing Unit). Google reconnait avoir développé ces unités de traitement de données pour faire face à l’explosion des coûts de calcul due au..Lire la suite
Ce programme de Facebook est quasi-infaillible. D’après les chercheurs de Facebook, ce système basé sur un processus d’apprentissage peut déterminer si deux visages photographiés appartiennent à la même personne avec une performance de 97,25 %.
Un système d’apprentissage et de classification a « découvert », par lui-même, le concept de chat. Dans le cadre de Google Brain, le projet de deep learning de la firme américaine, un système d’apprentissage et de classification basé sur des..Lire la suite
L’assistant de commande vocale d’Apple comprend et répond. Cette interface homme-machine comprend les instructions verbales données par les utilisateurs et répond à leurs requêtes. Elle repose sur la reconnaissance vocale, le traitement du langage naturel oral et la synthèse vocale.
Ce programme d’intelligence artificielle conçu par IBM remporte le jeu télévisé Jeopardy. Watson a été conçu dans le but de répondre à des questions formulées en langage naturel. Il a remporté le jeu télévisé Jeopardy : il est capable de..Lire la suite
Le Tianhe-1 est le premier à intégrer le TOP500 des plus puissants supercalculateurs. Installé au National Supercomputing Center, à Tianjin en Chine, le Tianhe-1 atteint théoriquement 4,7 PFlops et 2,57 PFlops sous Linpack. Ses performances consacrent également les GPU comme..Lire la suite
Elle est franchie par le supercalculateur Roadrunner d’IBM. Un pétaflops : 1015 opérations par seconde et une vraie rupture technologique : Roadrunner qui est le premier supercalculateur hybride, utilisant à la fois des processeurs généralistes et des « accélérateurs ». IBM a utilisé..Lire la suite
TEAM
RÉDACTRICE EN CHEF : ISABELLE BELLIN – EXPERTISE : ARNAUD SALOMON