Word embedding
Word embedding : Le word embedding désigne un ensemble de techniques de machine learning qui visent à représenter les mots ou les phrases d’un texte par des vecteurs de nombres réels, décrits dans un modèle vectoriel (ou Vector Space Model). Ces nouvelles représentations de données textuelles ont permis d’améliorer les performances des méthodes de traitement automatique des langues (ou Natural Language Processing), comme le Topic Modeling ou le Sentiment Analysis.
Le word embedding repose sur la théorie linguistique fondée par Zelling Harris et connue sous le nom de Distributional Semantics. Cette théorie considère qu’un mot est caractérisé par son contexte, c’est à dire par les mots qui l’entourent. Ainsi, des mots qui partagent des contextes similaires partagent également des significations similaires. Les algorithmes de word embedding sont le plus souvent employés pour décrire des mots à travers de vecteurs numériques, mais ils peuvent également être utilisés pour construire des représentations vectorielles de phrases entières, de données biologiques comme les séquence d’ADN, ou encore des réseaux représentés comme des graphes.
Il existe plusieurs approches de word embedding. Les premières remontent aux années 1960 et reposent sur des méthodes de réduction de dimensionnalité. Plus récemment, de nouvelles techniques basées sur des modèles probabilistes et des réseaux de neurones, comme Word2Vec, ont permis d’obtenir de meilleures performances.
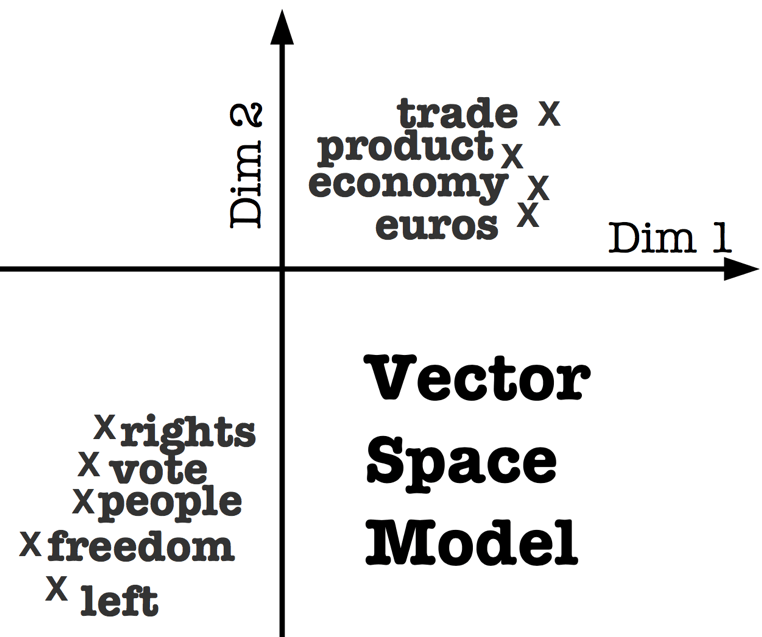
Dans l’exemple suivant, on schématise plusieurs termes ainsi que leurs représentations vectorielles bidimensionnelles. Les mots représentés, s’organisent en deux groupes, l’un relève de l’économie (trade, product, economy, euros) et l’autre appartient au champ lexical politique (rights, people, freedom, left).