
Word2Vec
Word2Vec : Cet algorithme de word embedding est parmi les plus connus. Il a été développé par une équipe de recherche de Google sous la direction de Tomas Mikolov. Il repose sur des réseaux de neurones à deux couches et cherche à apprendre les représentations vectorielles des mots composant un texte, de telle sorte que les mots qui partagent des contextes similaires soient représentés par des vecteurs numériques proches.
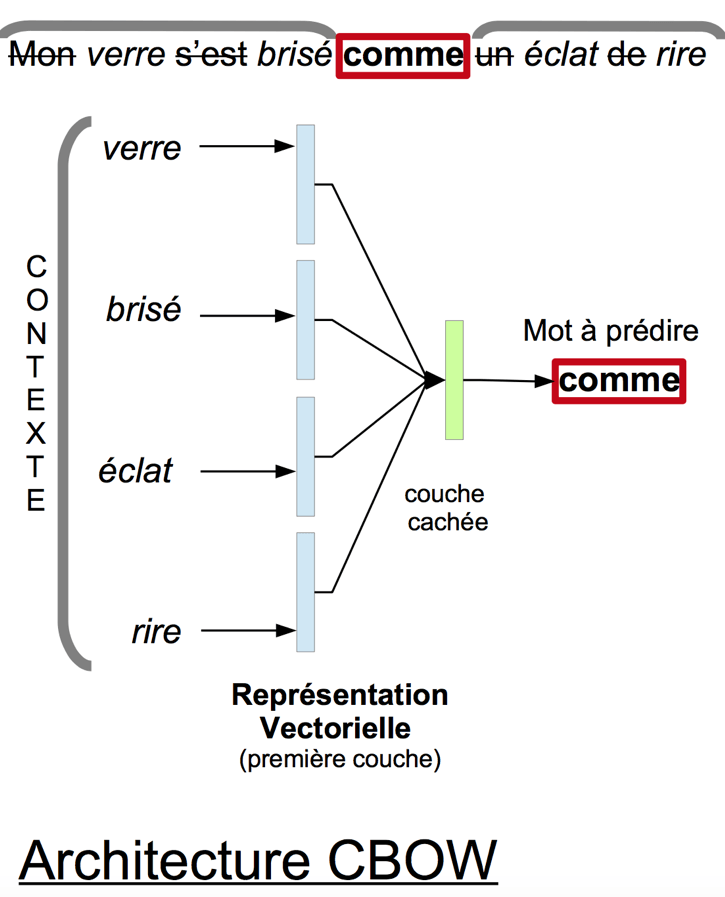
Word2Vec possède deux architectures neuronales, appelées CBOW et Skip-Gram, parmis lesquelles l’utilisateur peut choisir. CBOW reçoit en entrée le contexte d’un mot, c’est à dire les termes qui l’entourent dans une phrase, et essaye de prédire le mot en question. Skip-Gram fait exactement le contraire : elle prend en entrée un mot et essaye de prédire son contexte. Dans les deux cas, l’entraînement du réseau se fait en parcourant le texte fourni et en modifiant les poids neuronaux afin de réduire l’erreur de prédiction de l’algorithme [1].
Word2Vec possède différents paramètres, dont les plus importants sont :
– La dimensionnalité de l’espace vectoriel à construire, c’est à dire le nombre de descripteurs numériques utilisés pour décrire les mots (entre 100 et 1000 en général).
– La taille du contexte d’un mot, c’est à dire le nombre de termes entourant le mot en question (les auteurs suggèrent d’utiliser des contextes de taille 10 avec l’architecture Skip-Gram et 5 avec l’architecture CBOW).
Étant donné que Word2Vec n’est composé que de deux couches, cet algorithme est rapide à entraîner et à exécuter, ce qui se révèle être un avantage important par rapport à d’autre méthodes de word embedding.
Les schéma suivant illustre l’architecture CBOW, appliquée au dernier vers du poème de Guillaume Apollinaire “Nuit rhénane”. Dans cet exemple, les mots considérés comme trop communs, appelés aussi “mots outils” ou “stop words” sont éliminés des données fournies au réseau de neurones. La première couche du réseau projette chaque mot du contexte (en gris) vers sa représentation vectorielle (en bleu). Puis la couche cachée (en vert) analyse ces représentations vectorielles afin de tenter de prédire le mot central (encadré en rouge).
[1] Le plus souvent l’entraînement se réalise en utilisant un algorithme de descente de gradient stochastique (SGD).
+ Retour à l'index