

Le marché convoité de la valorisation des données juridiques
Les Legaltech, ces start-up qui appliquent des technologies informatiques au droit, se sont multipliées depuis 2016 et la promesse de numérisation des données de justice. Beaucoup évoquent des outils à base d’intelligence artificielle. Qu’en est-il ? Quelle que soit leur qualité pour rechercher ou analyser des informations dans la jurisprudence ou dans des contrats, les Legaltech bouleversent les pratiques.
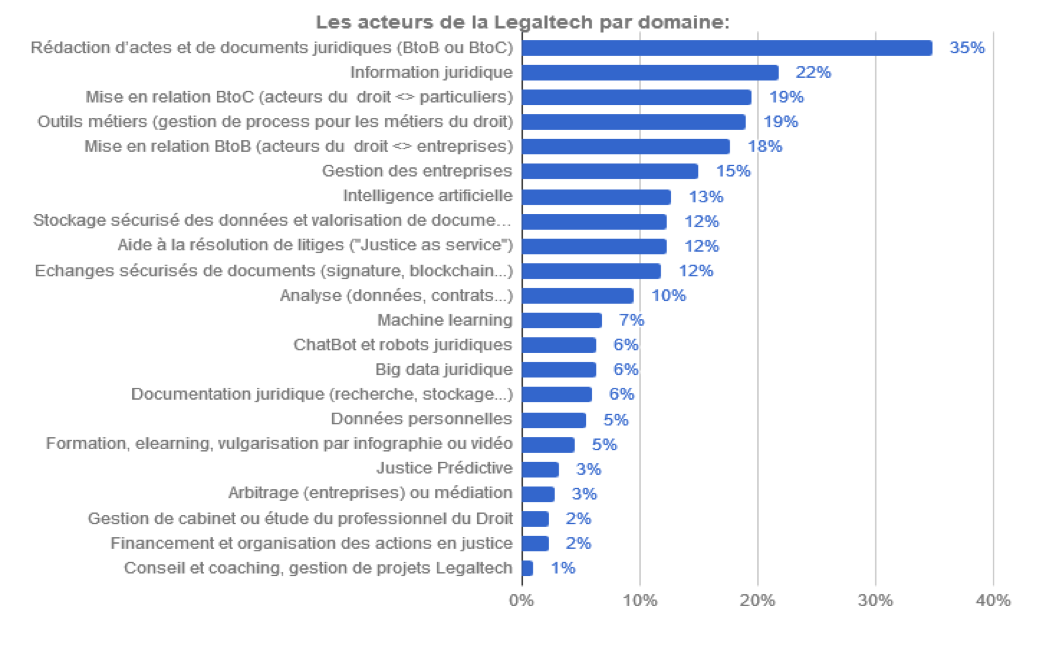
Le Village de la justice, site web de la communauté des métiers du droit, répertorie quelques 220 acteurs et services Legaltech dans son Guide et observatoire de la Legaltech et des start-up du droit (voir ci-dessous, données actualisées en juin 2019). Environ un tiers de ces start-up font de la génération automatisée d’actes et documents juridiques (35 %), les autres se répartissent entre information juridique, mise en relation de particuliers ou des entreprises avec des avocats, création d’outils métiers pour les avocats ou les juristes d’entreprise, stockage de données, résolution de litiges en ligne, analyse de contrats, ou encore justice prédictive.
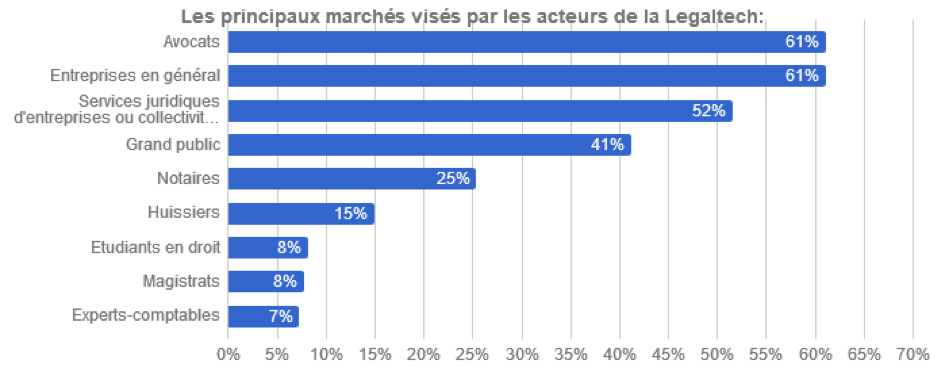
Toujours selon le Village de la justice, ces Legaltech s’adressent majoritairement aux avocats, aux entreprises (directions juridiques, DRH), aux services juridiques, aux notaires ou encore aux juges mais aussi au grand public et aux experts-comptables (voir schéma ci-dessous). Leurs outils sont en général disponibles sur abonnement.
Qui fait quoi ?
Parmi ces start-up, lesquelles utilisent du machine learning (en faisant émerger des règles mathématiques dans les données) voire du deep learning avec des algorithmes à base de réseaux de neurones profonds ? Très peu, malgré les promesses de leurs sites web, notamment parce que 70 à 80 % des Legaltech sont créées par des avocats qui n’ont pas le savoir-faire techno. Et pour quoi faire ?
« La valorisation des données juridiques intéresse deux grandes catégories d’acteurs, explique Michaël Benesty, data scientist chez Lefebvre-Sarrut et ancien avocat fiscaliste : d’un côté les entreprises, pour analyser des contrats ou la doctrine juridiqueLa doctrine juridique est l’ensemble des opinions données par les universitaires et les juristes – ce n’est pas une « source de droit » mais elle fait autorité. en tant que mode d’emploi, par exemple dans le cadre d’un licenciement ; de l’autre, les avocats et les magistrats pour analyser des décisions de justice, et faire de la justice prédictive (pour évaluer leurs chances de succès dans un litige, dégoter les arguments les plus pertinents ou estimer le montant d’éventuelles indemnités). »
Point commun des Legaltech les plus tech : l’utilisation d’algorithmes de traitement du langage naturel (NLP en anglais pour Natural Language Processing) car le droit est en général écrit de façon très codifiée. « On peut distinguer deux niveaux d’applications et donc d’outils développés, résume Alexandre Grux, fondateur et CEO d’Hyperlex, une start-up qui fait de l’analyse automatique de contrats : premier niveau que l’on retrouve dans toutes les Legaltechs, la recherche d’information (voir l’infographie sur les différentes méthodes de valorisation de données), avec des moteurs de recherche (pour repérer, classer des dates, des montants, des clauses de contrats, des types de contentieux, etc.) ; second niveau, l’analyse prédictive pour suggérer une décision à prendre sur la base de faits ou causes similaires avec des systèmes d’aide à la décision. In fine, ce sont les mêmes algos que l’on travaille sur des contrats ou des données juridiques, et les mêmes que ceux qui sont utilisés dans de nombreuses autres applications comme en finance ou en médecine. »
Plus de buzz que d’IA
Mais très peu de Legaltech utilisent du machine learning et de l’IA au sens où les règles de classification ou de décision sont apprises automatiquement par la machine à partir des données. C’était le cas du précurseur français, Supra Legem, un moteur de recherche open source développé par Michaël Benesty, fermé mi 2018 à la suite de la levée de boucliers dont il a fait l’objet après avoir publié le nom de magistrats dans des jugements en matière de droit des étrangers (obligation de quitter le territoire français ou OQTF). Chacun reconnaît néanmoins la qualité de l’outil, à base de réseaux de neurones, initialement créé pour analyser et filtrer les décisions de l’administration. Depuis, la loi de programmation et de réforme de la justice, promulguée en mars 2019, stipule « les données d’identité des magistrats et des membres du greffe ne peuvent faire l’objet d’une réutilisation ayant pour objet ou pour effet d’évaluer, d’analyser, de comparer ou de prédire leurs pratiques professionnelles réelles ou supposées » (article 33). Elle prévoit à ce titre une peine d’emprisonnement jusqu’à cinq ans et 300 000 euros d’amende.
La plupart des Legaltechs font de l’automatisation à partir de modèles d’arbres de décision dont les règles sont définies « à la main ». Ce qui peut donner de très bons résultats et à moindre coût. « Beaucoup de moteurs de recherche sont fondés sur des analyses statistiques, des systèmes experts et de la synonymie contextuelle automatique grâce à des systèmes d’analyse de chaînes de caractères et d’expressions régulières (regexLes regex (regular expression) restent un outil très efficace pour extraire rapidement des éléments spécifiques d’un contenu textuel. Exemple : détecter des montants à partir de chiffres suivis d’une devise. Mais ces règles ne sont pas exhaustives.) », précise Emmanuel Barthe, qui rappelle que le NLP façon machine learning date seulement de 2013, quand Google a mis en open source son logiciel Word2vec qui devine les synonymes d’un mot grâce aux autres mots du contexte.
Il souligne qu’il existe au moins trois utilisations que les cabinets d’avocats et les directions juridiques peuvent aisément déployer à partir de produits IA à l’ancienne, sans apprentissage automatique : « L’analyse de documents (comme le font les américains dans leurs procédures d’e-discovery pour la recherche de preuves dans le cadre de procès parfois avec des montagnes de documents), audit de contrats (analyse d’une grande quantité de contrats pour en extraire certaines informations ou certaines clauses contestables par exemple en matière d’accord de confidentialité), utilisations d’outils de recherche ou de classification notamment à partir de la jurisprudence. »
Contrats ou données juridiques
« Le domaine de valorisation de données juridiques qui s’est le plus développé en France concerne probablement la génération automatique de contrats, sans apprentissage automatique », poursuit Emmanuel Barthe. Citons Gino LegalTech, start-up créée par Philippe Ginestié, avocat féru de nouvelles technologies qui teste des générateurs de contrats depuis… 1982, ou LexDev (avec un langage informatique et des arbres de décisions). Depuis peu, deux start-up françaises (Hyperlex et Softlaw) se sont spécialisées dans un tout autre domaine, particulièrement prometteur en termes d’automatisation via du machine learning : l’analyse automatique de contrat (article à venir).
L’autre grand domaine d’implémentation des Legaltech concerne la justice et notamment ce qu’on appelle la justice prédictive. On désigne ainsi les techniques permettant d’anticiper l’issue d’un procès, d’évaluer la probabilité d’une décision de justice à partir des caractéristiques des décisions passées, autrement dit de la jurisprudence. « Cela correspond davantage à une tendance technologique s’appuyant sur la prolifération de données numériques et le développement de nouvelles méthodes d’extraction de connaissances liées à l’IA, pour réaliser des estimations chiffrées dans divers domaines intéressant le milieu judiciaire », constatent les auteurs d’un livre blanc sur les enjeux éthiques de la justice prédictive. Mais mettre du quantitatif dans la justice n’est pas anodin (voir l’article 2 du dossier à venir).
« La justice devrait être un champ d’application privilégié pour le machine learning, souligne pourtant Jacques Lévy Véhel, fondateur de Case Law Analytics (voir encadré). Le droit peut être vu comme un système complexe sur lequel on a beaucoup de données et dont il faut trouver les règles. Mais il a cela de spécifique qu’il touche à l’humain (comme la médecine), qu’il faut préserver la confidentialité et que la prévision de décisions de justice risque d’influencer les décisions ultérieures. » De fait, le sujet est particulièrement sensible du côté des magistrats. Au-delà de cela, il est particulièrement difficile de se faire une idée des méthodes utilisées par les uns et les autres, tout comme des résultats obtenus. Probablement parce que le marché est limité du côté des avocats, principaux intéressés en matière de justice prédictive, et par manque de données juridiques en open data (voir prochain article). Résultat : quelle que soit la qualité de leurs outils, les pratiques de ces certaines de ces start-up ne sont pas forcément vertueuses, parfois en violation de la loi et les procès se multiplient.
Comme le rappelle Emmanuel Barthe, le meilleur moyen de juger ces solutions est de les tester. Parmi les start-up françaises les plus en vue, citons Doctrine (en procès avec l’ordre des avocats de Paris) qui propose un moteur de recherche des textes de lois et de la jurisprudence ; Predictice (en procès ou litige avec Doctrine et LexisNexis) qui développe un moteur de recherche des décisions de justice et de la doctrine et un outil d’analyse pour évaluer les chances de succès et les indemnités de contentieux ou encore Lexbase qui analyse son fonds de jurisprudence avec son outil, Legalmetrics.
Pour en savoir plus :
- Article du blog d’Emmanuel Barthe (Precisement.org)
- Les enjeux éthiques de la justice prédictive (livre blanc de Science Po fait en collaboration avec Predictice)
Isabelle Bellin





