

Hyperlex ou l’analyse automatique de contrats
⏱ 6 minHyperlex, start-up très « tech » parmi les Legaltech, a levé 4 millions d’euros le mois dernier. Cette jeune pousse française exploite et développe l’état de l’art des algorithmes dans un outil d’intelligence artificielle pour analyser automatiquement les contrats et en extraire les données importantes. Entretien avec son CEO, Alexandre Grux.
Que propose Hyperlex ?
Alexandre Grux : Un moteur de recherche en ligne (en Saas) pour gérer et analyser automatiquement des contrats. De quoi faire gagner du temps et éviter des erreurs et des contentieux aux directions juridiques et achats des entreprises, mais aussi aux cabinets d’avocats et aux études de notaires. Prenons un exemple : récemment, avec le déploiement du RGPD [lire l’article, « Données personnelles : qui a accès à quoi ? #entreprises » NDLR], la plupart des entreprises européennes ont dû revoir de fond en comble, et à la main, leurs engagements contractuels et modifier leurs éléments portant sur les données personnelles, sous peine de risquer une amende de 4 % de leur chiffre d’affaire mondial. À la main, cet exercice peut durer des mois, et donc coûter très cher. Quand on sait que toutes les 10 minutes quelque part dans le monde, une réglementation change, on comprend qu’il est critique pour les entreprises d’avoir une idée très claire de leurs engagements contractuels, et de pouvoir intervenir rapidement pour faire des vérifications ou se mettre en conformité. Or, si la gestion de contrats peut sembler un exercice simple sur un faible volume, c’est une autre affaire pour une grande entreprise, qui doit souvent traiter plusieurs dizaines, voire centaines, de milliers de contrats. Sur ces volumes d’informations, disposer d’un outil doté d’intelligence artificielle (IA) va devenir la norme.
Combien êtes-vous ? Qui sont vos clients ?
A. G. : J’ai créé Hyperlex avec Alexis Agahi en septembre 2017. Nous sommes une vingtaine aujourd’hui, dont 4 data scientists, et nous avons une trentaine de clients, dont Rakuten, Zadig & Voltaire, des institutionnels, un cabinet d’avocats, la Chambre des Notaires de Paris, une étude d’huissier, ou encore l’Union des industries et métiers de la métallurgie. Notre outil leur permet de trier leurs contrats pour les ranger et y accéder plus rapidement, y retrouver des clauses précises ou des données contractuelles (dates, montants…) avec un système d’alertes automatiques, générer automatiquement une synthèse pour faciliter la prise de décision.
Quelle est l’originalité de votre solution ?
A. G. : Le défi auquel nous nous sommes attelés est de retrouver une information, comme une clause, dans n’importe quel document contractuel, y compris des documents scannés. Concrètement, nous utilisons plusieurs IA (voir schéma). Tout d’abord la reconnaissance d’éléments visuels (dont l’Optical Character Recognition ou OCR). La machine va être capable de lire l’image, d’en reconnaître les caractères, tampons, signatures, paraphes, logos… et de les exploiter. On peut ainsi vérifier que l’on possède bien dans ses archives la dernière version signée et paraphée et non une version provisoire. Cette IA est également capable de transformer des textes « bruités » avec des caractères non reconnus, où il manque un mot, ou de vieux documents en version exploitable dans notre moteur de recherche.
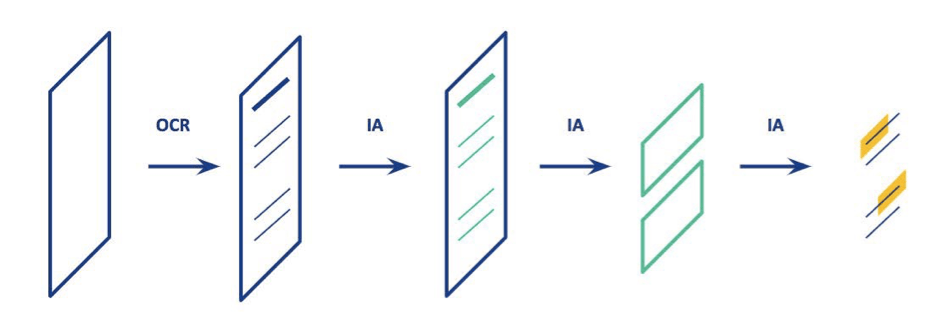
Nous utilisons bien sûr la reconnaissance sémantique et le traitement du langage naturel (NLP en anglais pour Natural Language Processing) pour reconnaître le type de contrat en fonction de son ensemble de mots clés, même sans titre. L’IA reconnaît également si le document contient des blocs de texte, comme des clauses contractuelles et peut les extraire du contrat. Elle reconnaît bien sûr aussi les éléments clés comme les dates, les montants, les durées, les contreparties, les noms de société…
Autrement dit, vous agrégez plusieurs solutions selon les cas ?
A. G. : C’est cela. Nous sommes, à ma connaissance, la seule Legaltech à appliquer tous les algos possibles, d’analyse d’image comme de texte, IA symbolique ou machine learning, y compris réseaux de neurones. Nous nous demandons, à chaque fois, comment fait un humain pour résoudre le problème, et nous choisissons la stratégie en conséquence. Cela nous permet de choisir le meilleur de l’état de l’art, quel que soit le document, là où la plupart de nos concurrents utilisent des systèmes d’analyse de chaînes de caractères et d’expressions régulières (regexLes regex (regular expression) restent un outil très efficace pour extraire rapidement des éléments spécifiques d’un contenu textuel. Exemple : détecter des montants à partir de chiffres suivis d’une devise. Mais ces règles ne sont pas exhaustives.) et des règles métier. Difficile dans ce cas de retrouver des informations au milieu d’un tas de contrats de manière robuste sans moyen sémantique pour les différencier et s’adapter à la forme de rédaction. De manière générale, les meilleures solutions sont celles qui auront été le mieux entraînées, donc focalisées sur un cas d’usage : les accords de confidentialité pour Lawgeex, les cas de fusion/acquisition pour Kira Systems et iManage ou les éléments liés à la gestion de contrats pour nous.
Sur quelles données votre IA est-elle entraînée ?
A. G. : Nous avons deux enjeux. Le premier est d’apporter à nos clients une IA pré-entraînée sur les sujets qui sont les plus communs pour leur métier. Nous réalisons ce travail sur des données publiques – des contrats que l’on trouve sur internet en libre-service. L’IA est entraînée à partir d’exemples donnés par des juristes. Ils n’ont qu’à montrer à la machine dans un texte comment s’appelle telle ou telle clause, où est la date de fin de contrat, la durée de préavis, etc. Cette phase d’apprentissage « magique », très intuitive, est hyper importante, surtout pour un public qui n’est pas habitué à l’informatique. Le deuxième enjeu est que notre technologie sache très rapidement travailler sur les contrats de nos clients, qui possèdent des caractéristiques propres du fait de leur industrie, de leur produit, etc. Il y a énormément de variabilités et il est très difficile de prétendre proposer une IA déjà entraînée sur tout. Nous avons préféré développer des méthodes qui permettent à notre solution de s’entraîner très rapidement sur de nouvelles données, celles de nos clients, sans même les solliciter.
Expliquez-nous cela. Concrètement, comment le client utilise-t-il votre outil ?
A. G. : Le client dépose son contrat dans notre espace sécurisé et centralisé de stockage et de partage de documents. Il est analysé par notre IA pour en extraire les informations recherchées comme une date d’échéance. Cela va très vite sans qu’il y ait besoin d’avoir identifié ces informations au préalable dans d’autres contrats de l’entreprise. Parallèlement, nos mises à jour génèrent de nouvelles identifications d’informations. Si l’utilisateur les valide, cela enrichit l’IA. Mais jamais les données des utilisateurs ne sont partagées. Nous utilisons par ailleurs une stratégie de cryptographie des données assez innovante, avec des clés de chiffrement stockées chez les clients eux-mêmes, et non chez Hyperlex. À chaque fois que nous améliorons l’IA, cela laisse une trace chez le client, et à tout moment il peut stopper nos accès tout en continuant à utiliser son produit.
Pourquoi l’analyse automatique de contrats est-elle un domaine prolifique en IA juridiques ?
A. G. : C’est le cas aux États-Unis. Pas en France, où nous ne sommes que deux start-up, Hyperlex et Softlaw. Ces IA se sont développées outre-Atlantique pour la recherche de preuves dans le cadre de procès, ce qu’on appelle l’e-discovery, parfois avec des montagnes de documents. Cette analyse, d’abord manuelle, s’est progressivement industrialisée et a donné naissance à quelques belles start-up qui restent cependant très anglophones. Le marché et la pratique existaient déjà, elle s’est juste modernisée avec les nouvelles méthodes de machine learning. Enfin, on peut aussi rappeler que le langage juridique est très codifié à la base, c’est presque un langage informatique. Les algorithmes captent assez bien les « patterns » qualifiant les objets et expressions juridiques.
Après avoir levé 1 million d’euros en février 2018 en amorçage, vous venez de boucler un tour de table en série A de 4 millions d’euros auprès du fonds Elaia, d’Axeleo Capital et de vos investisseurs historiques ISAI et Kernel Investissements. Que comptez-vous faire de cet argent ?
A. G. : Hyperlex a un ADN profondément technologique, plus de 60 % des effectifs sont consacrés à notre R&D. Cette levée de fonds va nous permettre de maintenir notre avance technologique mais aussi d’accélérer notre commercialisation en France avec l’embauche de commerciaux. Nous allons continuer à l’entraîner à de nouvelles langues (des tests sont en cours en allemand et en italien). Nous allons également améliorer sa précision et sa fiabilité. La fiabilité est un gros challenge. Il ne faut pas que les utilisateurs doutent de la machine. Pour cela, il faut d’une part que l’IA soit capable de donner des indicateurs de confiance quand elle sait, d’autre part qu’elle précise quand elle ne sait pas. L’humain peut passer du temps à compléter le travail de la machine si besoin, mais il faut que celle-ci soit en mesure de le lui demander.
Propos recueillis par Isabelle Bellin





