

La revanche des neurones
⏱ 5 minÀ l’heure où les réseaux de neurones sont adulés et considérés comme le fondement naturel de nombreux développements d’intelligence artificielle, Dominique Cardon, Jean-Philippe Cointet, chercheurs au Medialab de Science Po, et Antoine Mazières, post-doctorant au Centre Marc-Bloch (CMB), à Berlin, rappellent que ces techniques d’apprentissage ont pourtant longtemps été moquées (1).
« Le mec, il arrive avec une grosse boîte noire de deep, il a 100 millions de paramètres dedans, il a entraîné ça et il explose tout le domaine… Il met 10 points à tout le monde !… Grosso modo cela foutait en l’air dix ans d’intelligence, de tuning, de sophistication. » Ces propos, bruts et anonymisés, sont ceux de chercheurs français en informatique qui ont participé à la renaissance des réseaux de neurones et racontent ici la présentation en octobre 2012 des résultats de l’équipe de Geoffrey Hinton au challenge ImageNet lors de la conférence de reconnaissance d’images ECCV (European Conference on Computer Vision). Ils sont publiés dans un article de la revue Réseaux (1) par Dominique Cardon, Jean-Philippe Cointet, chercheurs au Medialab de Science Po, et Antoine Mazières, post-doctorant au Centre Marc-Bloch (CMB), à Berlin. Cet article propose une intéressante rétrospective historique de l’histoire de l’intelligence artificielle (IA), que nous avons résumé ici.
Deux mondes qui s’opposent
Reprenons les résultats évoqués plus haut. Comment une méthode d’apprentissage proposant le traitement le plus « brut » possible des entrées, évacuant toute modélisation explicite des caractéristiques des données et optimisant la prédiction à partir d’énormes échantillons d’exemples, produit ces résultats spectaculaires ? Cette méthode de réseaux de neurones et le « calcul inductif » sur lequel elle se fonde, qui consiste à confier à la machine le soin de produire des prédictions pertinentes en apprenant à partir des données, ne sont en fait pas nouveaux. L’idée date des débuts de la cybernétique, dont se démarquait justement radicalement l’IA, vocable inventé en 1955 par John McCarthy.
Il est intéressant de rappeler à quel point ces deux manières de concevoir et de programmer le fonctionnement « intelligent », à savoir le courant connexionniste pour les réseaux de neurones – calcul massivement parallèle dont le comportement signifiant résulte des interactions – et le courant symbolique pour l’IA avec ses règles logiques et ses systèmes experts – calcul à partir de symboles qui ont une valeur sémantique de représentation -, ont été en concurrence (fig 1). Autrement dit, le deep learning était marginalisé avant les années 2010 alors qu’il apparaît aujourd’hui comme la méthode phare de l’IA.
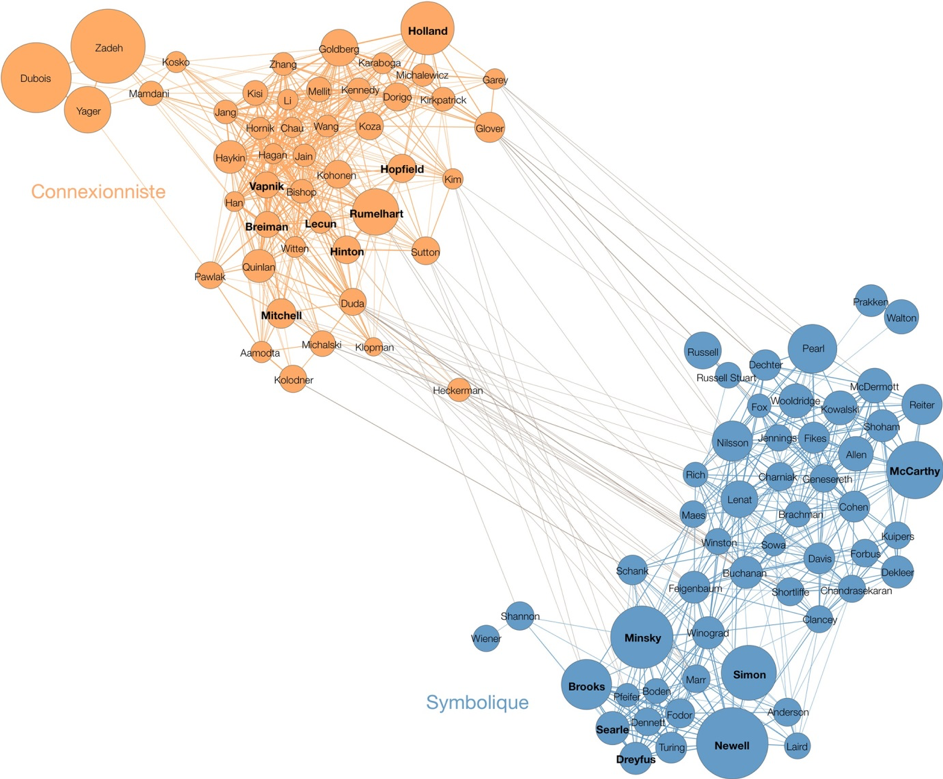
Fig 1 : Réseau de co-citations des 100 auteurs les plus cités par les publications scientifiques mentionnant Artificial Intelligence
Et l’évolution de l’influence académique des deux courants entre 1935 et 2005 est particulièrement révélatrice de la controverse scientifique entre ces deux communautés (fig 2)
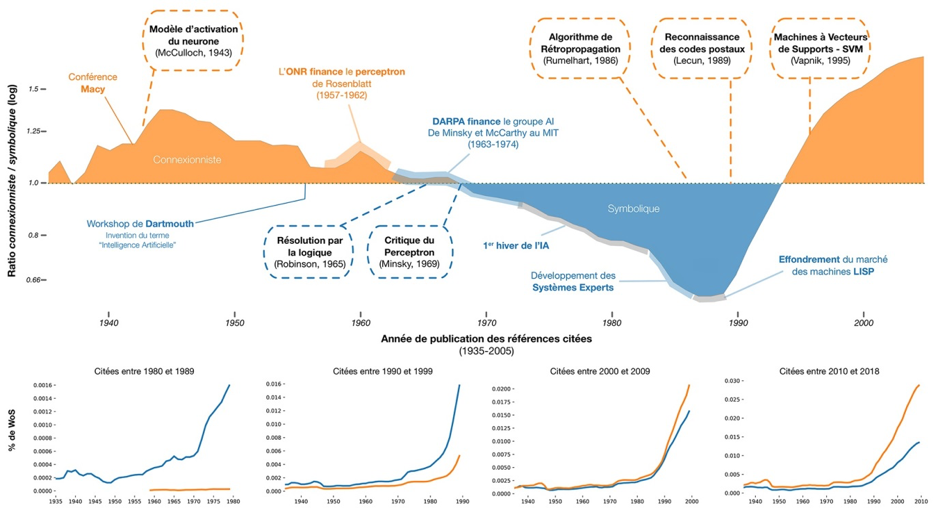
Fig 2 : Évolution de l’influence académique des approches connexionniste et symbolique
L’idée de modéliser mathématiquement un réseau de neurones date en réalité de 1943 avec les travaux fondateurs de Warren McCulloch et Walter Pitts qui font toujours référence. Elle sera rapidement associée aux notions d’apprentissage avec les contributions de Donald O. Hebb. Les premières machines intelligentes de la cybernétique (dont l’emblématique Perceptron de Frank Rosenblatt conçu pour la reconnaissance d’images, en 1957) seront basées sur ce modèle bio-inspiré de neurones formels. Leur principal axiome est d’incorporer la mesure de l’erreur en sortie comme une nouvelle entrée d’un système adaptatif.
Trop de promesses non tenues
Cette approche est balayée à partir de 1956 par les promoteurs de l’IA, dont John McCarthy et Marvin Minsky, qui prônent la modélisation du raisonnement via des règles, et s’arrogent le monopole de la définition de l’IA ainsi que les financements considérables associés, à coups de promesses et de dénigrement des réseaux de neurones. L’architecture des machines symboliques réserve un espace propre à la programmation selon la configuration de von Neumann comme dans les machines LISP optimisées pour le langage de programmation LISP, développé par John McCarthy pour l’IA. Le raisonnement prend le dessus sur la physiologie et le comportement humain.
Vers 1970, ce mode de calcul rationnel, organisé en étapes de suites d’opérations élémentaires, se révèle limité aux seuls mondes qu’il considère, comme le jeu d’échecs, et impossible à généraliser. Et le très critique Rapport Lighthill contribue à geler les financements. C’est le premier hiver de l’IA, auquel succédera un second printemps, avec l’avènement de calculateurs plus puissants permettant de traiter les connaissances spécialisées prélevées dans le savoir d’experts. Ces systèmes experts sont des cathédrales de règles qui s’appliquent très bien aux contextes scientifiques et industriels. Avec eux, les méthodes statistiques se développent avec des raisonnements de type inférentiel comme les arbres de décision, les forêts aléatoires ou les réseaux bayésiens.
Progressivement, dans les années 1990, avec la multiplication des données de moins en moins organisées, ce n’est plus l’information qu’elles portent qui permet de les rassembler, mais des critères d’optimisation. Dans ce contexte, à partir des années 1980, les réseaux de neurones vont se révéler plus efficaces, progressivement remis au goût du jour par des biologistes, des physiciens et des informaticiens. De nouvelles architectures de réseaux de neurones multicouches apparaissent comme les machines de Boltzmann et surtout la rétropropagation de gradient stochastique permettant de concevoir des systèmes comme Nettalk qui transforme des textes en phrases vocalisées. Avec la technique de convolution de Yann Le Cun, les premières applications industrielles des réseaux de neurones apparaissent, comme la reconnaissance de codes postaux et des montants des chèques. Mais le petit groupe qui soutient ces techniques (Geoffrey Hinton, Yann Le Cunet Yoshua Bengio) est isolé, avec pour principal soutien le Canadian Institute for Advanced Research (CIFAR).
Les succès du deep learning
D’autant plus qu’une méthode symbolique, les machines à vecteur de support (SVM) (ou méthodes à noyaux) se révèle efficace sur de petits datasets. Mais face au big data, de telles méthodes d’optimisation convexe ne font pas le poids, comparées à l’efficacité des prédictions du deep learning. Et la croissance exponentielle de la puissance des calculateurs grâce à la parallélisation et à l’utilisation des GPU va permettre d’entraînerde plus en plus vite les réseaux de neurones. Quant aux données, elles doivent être codées sous forme de vecteurs, ce qui est assez naturel pour les images, moins pour le texte pour lequel des techniques d’embedding (ou plongement) sont utilisées comme Word2vec. L’embedding s’étend progressivement à tous les domaines applicatifs et les calculs des réseaux de neurones continuent de gagner en efficacité.
Toutefois, le deep learning est loin de répondre à tous les besoins de l’intelligence artificielle. Il faut notamment définir les hyper-paramètres du calculateur, autrement dit les paramètres d’ajustement qui régissent le processus d’entraînement : le nombre de couches cachées, de neurones par couche, le choix de la fonction d’activation, du type d’optimisation, etc. Ces réglages de l’architecture du modèle se font par essais/erreurs et restent artisanaux, largement tributaires de l’habileté du programmeur. C’est l’un des principaux champs théoriques actuel.
L’heure serait-elle venue à une hybridation entre les approches symbolique et connexionniste ? Les auteurs recommandent de prêter attention de plus en plus à la composition des données, à l’architecture retenue et aux objectifs de supervision de l’apprentissage.
(1) Dominique Cardon, Jean-Philippe Cointet et Antoine Mazières, « La revanche des neurones. L’invention des machines inductives et la controverse de l’intelligence artificielle », Réseaux 2018/5 (n° 211), p. 173-220.
Isabelle Bellin





