BYOL apprend à bien représenter les images, sans supervision
⏱ 4 minL’apprentissage auto-supervisé, qui fait l’économie de ces coûteuses données étiquetées, fait des progrès notables ces derniers temps. En vision artificielle, une approche prometteuse a été récemment publiée par une équipe de DeepMind.
Les données étiquetées sont rares et chères, c’est pourquoi l’on espère beaucoup des progrès récemment annoncés dans le domaine de l’apprentissage auto-supervisé… qui en fait l’économie. Une publication majeure¹ sur ce thème a été présentée en décembre dernier à NeurIPS 2020 (Conference on Neural Information Processing Systems) par une équipe de DeepMind, une filiale de Google. Elle propose une nouvelle approche pour l’apprentissage de représentation d’images, qui répond au nom de BYOL.
BYOL signifie « Bootstrap Your Own Latent », ce qui n’est pas facile à traduire. Le mot « latent » renvoie à cet « espace latent » dans lequel les images sont représentées par les modèles. Un espace dont la dimensionnalité est très élevée (quelques centaines, voire quelques milliers de dimensions), et dans lequel des réseaux de neurones que l’on appelle « encodeurs » représentent chaque image par un vecteur comportant autant de composantes. BYOL, en l’occurrence, représente les images dans un espace à 2 048 dimensions.
Deux « vues » différentes de la même image
« Notre approche ne concerne pas une tâche particulière en vision artificielle, comme la classification, la segmentation ou la détection d’objets, mais cette fonction commune et centrale dont elles dépendent toutes, qu’est la représentation d’image », précise Michal Valko, qui a dirigé l’équipe qui a conçu et publié BYOL. Ce chercheur de l’équipe parisienne de DeepMind, est aussi membre de l’équipe Sequel à Inria Lille – Nord Europe.
« Notre modèle comporte deux réseaux de neurones, que nous appelons « online » et « target » (cible), et qui apprennent l’un de l’autre, précise le chercheur. À chaque cycle d’apprentissage, on présente à ces deux réseaux deux « vues« de la même image, choisie aléatoirement dans un jeu de données. Ces deux vues sont obtenues à partir de l’image originale en appliquant une série aléatoire « d’augmentations« , c’est-à-dire de transformations diverses, telles que : recadrage, retournement, modification des couleurs, de la luminosité, du contraste, floutage… »
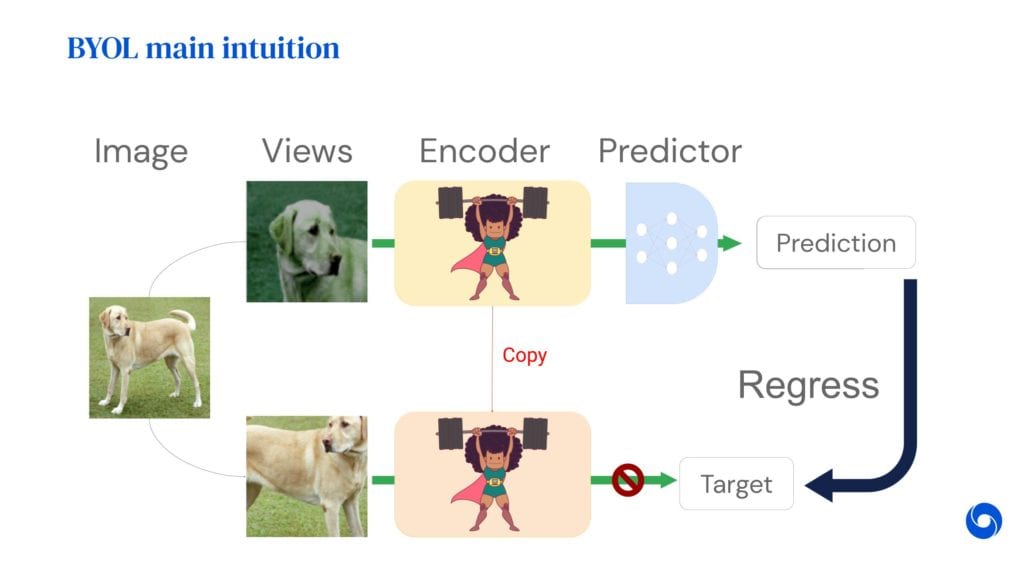
Au cours de l’apprentissage, les deux encodeurs de BYOL traitent deux « vues » différentes de chaque image et en fournissent chacun une représentation dans un espace « latent » à 4096 dimensions. Via un « prédicteur », la représentation de l’encodeur principal est confrontée à celle de l’encodeur « target ». Périodiquement, l’erreur est classiquement rétro-propagée dans l’encodeur principal, mais les poids de l’encodeur « target » sont mis à jour par une moyenne pondérée avec ceux de l’encodeur principal. Crédit : DeepMind.
Deux encodeurs qui apprennent l’un de l’autre
L’idée centrale est d’apprendre au premier réseau à prédire la représentation produite par le second, qui « voit » la même image initiale que lui, mais déformée d’une façon différente. L’objectif étant de produire une représentation des images peu sensible à ces déformations, et qui véhicule donc surtout l’essentiel, le contenu, et très peu les détails.
L’apprentissage de BYOL se fait en un certain nombre d’étapes, ou « époques » (jusqu’à 1 000). Au cours de chaque époque, tout le jeu de données choisi est traité, mais par lots (« batches »), typiquement de 4 096 images chacun. Dans le cas de la base ILSVRC (ImageNet Large Scale Visual Recognition Challenge), qui comporte 1 281 167 images, cela représente par exemple 312 lots de 4 096 images. Les deux réseaux apprennent de deux façons différentes. À l’issue du traitement de chaque lot d’images, l’erreur moyenne de prédiction est calculée pour le premier réseau (online), et la rétro-propagation du gradient est effectuée, à partir d’elle, sur les poids synaptiques de ses neurones. En revanche, les poids du second réseau (target) sont un peu révisés à partir des valeurs de celles du premier réseau. Une moyenne pondérée est effectuée entre les valeurs courantes de ses propres poids et une petite fraction de celles du réseau online. À chaque étape, le réseau target se rapproche ainsi un peu du réseau online, tout en restant différent, plus influencé par son passé.
Presque aussi bien que l’apprentissage supervisé
Pour ses deux encodeurs, ses deux pièces maîtresses, BYOL fait appel à des réseaux de neurones classiques du type ResNet. Dans la version standard, il s’agit de ResNet-50, donc à 50 couches, mais des essais ont aussi été effectués avec des ResNet à 100 et 200 couches, qui donnent des résultats améliorés, mais au prix, bien sûr, d’un coût accru en termes de puissance de calcul.
L’équipe de DeepMind a, bien entendu, évalué les performances de son bébé. Elle a ainsi constaté que sur une tâche de classification d’images typique sur ImageNet, BYOL obtenait dans sa version standard un score de 74,3 %, surpassant tous les modèles comparables entraînés par auto-apprentissage. Dans une version plus musclée, faisant appel à des ResNet-200, un score de 79.6 % a même été enregistré. Plus généralement, les performances de BYOL se situent en général à un ou deux pour cent de celles des meilleures approches relevant de l’apprentissage supervisé, la voie royale en vision artificielle.
Ces résultats laissent penser qu’à l’avenir, les progrès en vision artificielle pourraient être moins dépendants de la supervision et donc de l’existence de ces coûteuses bases de données étiquetées.
Pierre Vandeginste
1. Jean-Bastien Grill et al., « Bootstrap Your Own Latent: A new approach to self-supervised learning« , NeurIPS 2020. https://arxiv.org/pdf/2006.07733.pdf