

Détection de fraude à la carte bancaire : un casse-tête particulièrement stimulant pour les data-scientists
⏱ 6 minOlivier Caelen & Frédéric Oblé, Worldline, R&D High Processing & Volume Division
Problème extrêmement critique tant pour les entreprises que pour les particuliers, la fraude à la carte bancaire est un sujet complexe et passionnant du point de vue mathématique. Les algorithmes développés doivent être capables de s’adapter tout autant aux spécificités des données de transaction qu’à celles des fraudes. Un « jeu » de chat et de souris où le data scientist doit avoir un coup d’avance ! Voyons comment le problème se pose et quels types d’algorithmes y répondent.
Depuis 2015, le volume total de transactions par paiement électronique en Europe croit organiquement de 6,5 % par an. Ce type de transactions repose sur des algorithmes complexes qui peuvent être embarqués sur des terminaux physiques, être liés à des applications Web ou à des applications mobiles inter-opérant avec des data centres hautement sécurisés. L’ensemble de ces transactions représente un marché considérable de 577 milliards d’euros en 2018, un marché qui s’appuie fortement sur la confiance que l’ensemble des acteurs (banques, marchands, clients finaux) a dans la manière d’opérer ces systèmes. Or, parallèlement à cette forte hausse du volume des transactions électroniques, on assiste à une activité croissante des organisations mafieuses. Cela se traduit par une augmentation significative des cas de fraudes au paiement, autrement dit des cas de paiements électroniques non autorisés par le porteur de carte. Afin de réduire au maximum ces risques, les compagnies traitant les paiements électroniques – comme Worldline, filiale d’Atos – ont mis en place et développent des solutions de détection de la fraude. Celles-ci ont vocation à protéger aussi bien les porteurs de cartes, en vérifiant que les informations de leurs cartes ne sont pas utilisées sans leur consentement, que les marchands, en s’assurant que les informations des cartes qui leur sont soumises n’ont pas été préalablement volées.
Depuis plusieurs années déjà, ces systèmes de détection de fraude utilisent des algorithmes d’apprentissage automatique. Quelles sont les problématiques inhérentes à la détection de fraude dans le paiement ? Et quels sont les types d’algorithmes les mieux adaptés pour y faire face ? Précisons d’abord qu’un système de détection de fraude peut être source de deux types d’erreur. D’une part, il peut produire de fausses alertes sur des transactions légitimes – on parle alors de « faux positif » : le système détecte une fraude alors qu’il n’y en a pas – ce qui empêche un client de réaliser une transaction. D’autre part, il peut ne pas produire d’alerte sur un cas de fraude – on parle de « faux négatif ». Dans les deux cas, les mécanismes décisionnels du système de détection opèrent dans un contexte critique, avec un impact direct sur le client.
Des algorithmes séquentiels
Quelles sont les caractéristiques spécifiques des données des transactions de paiement ? Par essence, elles sont séquentielles et en très grande quantité. Pour les traiter, le modèle doit pouvoir utiliser une infrastructure dotée d’une mémoire interne conséquente et capable d’intégrer et de gérer très rapidement de gros volumes de données. Par ailleurs, ces données sont « non-stationnaires », pour deux raisons : soit du fait que les fraudeurs adaptent leurs stratégies aux méthodes de détection, soit du fait que les habitudes d’achat des clients changent au cours de l’année (fêtes, évènements notables, soldes, vacances…). Ces deux sources de non-stationnarité n’ont pas le même impact sur les performances des algorithmes. La première augmente plutôt les faux négatifs car les nouveaux types de fraude ne sont pas encore détectés par le système, alors que la seconde augmente plutôt les faux positifs car les variations de comportements d’achat d’un client peuvent être considérées par le système comme un comportement inhabituel et donc à plus haut risque de fraude. Pour garantir les meilleures performances, les systèmes de détection de fraude reposent donc sur des algorithmes séquentiels 1 qui ont l’avantage de s’adapter en temps réel (voir l’article du DAP sur l’apprentissage séquentiel dans le cas du ciblage des publicités, ndlr).
La fraude est un évènement rare en proportion des volumes de transactions légitimes – l’ordre de grandeur est, habituellement, d’une transaction frauduleuse sur mille. Tant mieux ! Mais, du point de vue du data scientist, cela a pour conséquence que l’ensemble des données d’apprentissage utilisées pour construire les modèles de détection est très fortement déséquilibré : le faible ratio de paiements frauduleux en regard de la quantité de transactions rend la fraude difficile à prédire avec des algorithmes classiques d’apprentissage. Deux solutions s’offrent au concepteur d’algorithmes : utiliser des méthodes de ré-échantillonnage des données pour réduire artificiellement ce déséquilibre afin de pouvoir utiliser des algorithmes d’apprentissage classiques 2 ou garder l’ensemble d’apprentissage tel quel mais utiliser une famille d’algorithmes d’apprentissage capable de traiter ce type de données fortement déséquilibré 3.
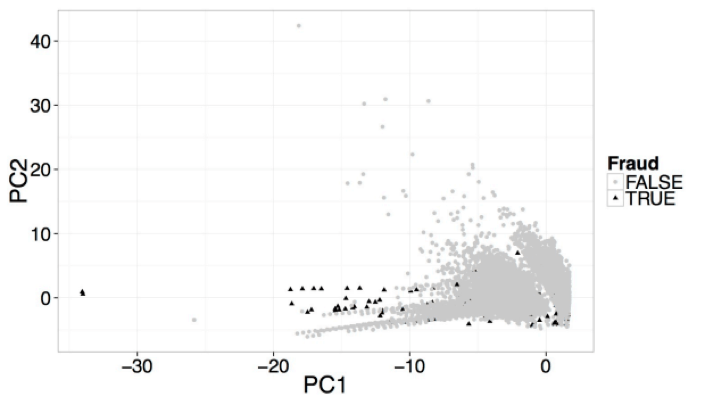
Sur cette projection d’un ensemble de transactions analysées en composantes principales dans un sous-espace de dimension 2, les points noirs représentent les transactions frauduleuses et les gris, les transactions légitimes. Nous pouvons observer dans le coin inférieur droit un chevauchement entre les deux types de transactions.
A l’aide de techniques de visualisation comme sur la figure ci-dessus, il est possible de mettre en lumière une dernière caractéristique des données de transaction de paiement qui complexifie parfois le problème : le « chevauchement » entre certains cas de fraudes et les transactions électroniques légitimes. Cela provient du fait que les fraudeurs, pour ne pas être détectés afin d’utiliser les informations de la carte volée le plus longtemps possible, s’efforcent d’adopter un comportement apparaissant comme « normal » du point de vue du système. Ce type de comportement demeure évidemment difficile à détecter. Pour y parvenir, le data scientist s’aide de méthodes telle que la création de nouvelles variables, qui permet, en quelques sortes, d’enrichir le contexte de nouvelles informations participant à l’identification de la fraude. Parmi les techniques permettant d’améliorer significativement les performances de détection, signalons des travaux de recherche récents sur l’injection d’informations de contexte sémantique dans un modèle de détection de fraude 4 ou la représentation des données de paiement sous la forme d’un graphe pour ensuite en extraire des variables supplémentaires 5.
Des algorithmes supervisés ou non supervisés ?
Dans ce contexte, où sont susceptibles d’apparaître des disruptions de comportement, la tentation est grande de mettre en œuvre des algorithmes d’apprentissage non supervisé, qui ont la capacité de « découvrir » des classements transaction frauduleuse / transaction légitime sans se baser sur des exemples de fraude passée. Malheureusement, ils sont aujourd’hui encore très difficiles à configurer car il existe une immense variété de comportements des porteurs de cartes. L’un des principaux défauts de ces algorithmes est qu’ils produisent des alertes dès qu’un individu semble avoir un comportement inhabituel, ce qu’il est très difficile de qualifier lorsque l’information collectée sur ces mêmes individus est faible. Ainsi, des milliers de « comportements inhabituels », mais néanmoins légitimes, se produisent chaque jour. Les algorithmes non supervisés produisent par conséquent énormément de faux positifs, ce qui les disqualifie en première approche pour un système de détection industriel.
Sur la base de l’historique des transactions frauduleuses, les algorithmes d’apprentissage supervisé généralisent, quant à eux, un classement qui leur permet de considérer chaque nouvelle transaction comme légitime ou frauduleuse. Ils ne sont pas pour autant la panacée non plus. Pour comprendre pourquoi, nous devons nous demander comment est constitué cet historique, autrement dit, comment est détectée une fraude. En règle générale, il existe deux sources : soit des experts humains qui analysent les alertes manuellement (et trouvent de vrais positifs), soit un porteur de carte lorsqu’il découvre un usage frauduleux de sa carte (un faux négatif). Dans le premier cas, la correction de supervision est relativement rapide mais il faut que la transaction ait fait l’objet d’une alerte. Les détections frauduleuses sont donc détectées mais seulement pour un sous-ensemble de transactions (on parle de jeu de données « semi-supervisé »). Dans le second cas, le temps d’identifier une transaction comme frauduleuse peut être plus long car il faut que le porteur de carte la détecte. Les algorithmes d’apprentissage doivent donc être capables de comprendre ces deux mécanismes : être en mesure de tirer profit de données semi-supervisées obtenues à court terme mais aussi des données supervisées obtenues à long terme, ce que les algorithmes supervisés classiques ne savent pas faire 6.
Les performances des algorithmes de détection de fraude sont des secrets industriels bien gardés car il en va de la compétitivité et de la sécurité des opérateurs. Selon la parabole couramment utilisée, la bataille entre le glaive et le bouclier fait rage sur le théâtre de la fraude. Autant de challenges particulièrement stimulants en termes d’ingénierie et de mathématiques pour résoudre un problème industriel majeur.
Références
1 Jurgovsky Johannes , et al. « Sequence Classification for Credit-Card Fraud Detection » Expert Systems With Applications (2018).
2 Dal Pozzolo Andrea, et al. « When is undersampling effective in unbalanced classification tasks?. » Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Cham, 2015.
3 Dal Pozzolo Andrea, et al. « Using HDDT to avoid instances propagation in unbalanced and evolving data streams. » Neural Networks (IJCNN), 2014 International Joint Conference on. IEEE, 2014
4 Ziegler Konstantin, et al. « Injecting Semantic Background Knowledge into Neural Networks using Graph Embeddings. » Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), 2017 IEEE 26th International Conference on. IEEE, 2017.
5 Lebichot Bertrand, et al. » A graph-based, semi-supervised, credit card fraud detection system. » International Workshop on Complex Networks and their Applications, 2016.
6 Dal Pozzolo Andrea, et al. « Credit card fraud detection: a realistic modeling and a novel learning strategy. » IEEE transactions on neural networks and learning systems, 2017.





