

Ithaca, le réseau de neurones de DeepMind qui reconstitue des inscriptions antiques lacunaires
⏱ 4 minIthaca est un bel exemple de recherche collaborative dans le domaine de l’épigraphie, la science qui étudie les inscriptions anciennes sur des supports durables (pierre, métal, céramique…). Ce réseau de neurones “devine” les parties manquantes de textes en grec ancien, les date et les situe.
Yannis Assael et Thea Sommerschield faisaient leur doctorat ensemble à l’université d’Oxford quand ils ont eu l’idée d’unir leurs compétences. Yannis, désormais chercheur chez DeepMind, division de Google dédiée à l’intelligence artificielle, développait des algorithmes de machine learning quand Thea, qui travaille aujourd’hui avec l’université Ca’ Foscari de Venise et celle de Harvard, étudiait l’histoire ancienne.
Ils ont eu l’idée d’unir leurs compétences et se sont lancé un défi : déchiffrer les inscriptions anciennes comme celles du marbre de l’île grecque de Paros exposé au musée d’art et d’archéologie Ashmolean à Oxford, daté entre 264 et 263 avant J.-C. Les inscriptions y sont difficilement déchiffrables même pour un familier du grec ancien : il manque des lettres, des mots et des phrases du fait de la dégradation du support. Avec Jonathan Prag, chercheur chez DeepMind et à l’université d’Oxford, ils avaient déjà développé en 2019 un réseau de neurones pour l’épigraphie, baptisé Pythia. Le nouveau modèle qu’ils ont publié1 en mars dernier dans la revue Nature, Ithaca, est non seulement plus puissant pour déchiffrer les parties de texte disparues mais il est aussi capable d’en déterminer l’origine géographique et de les dater.
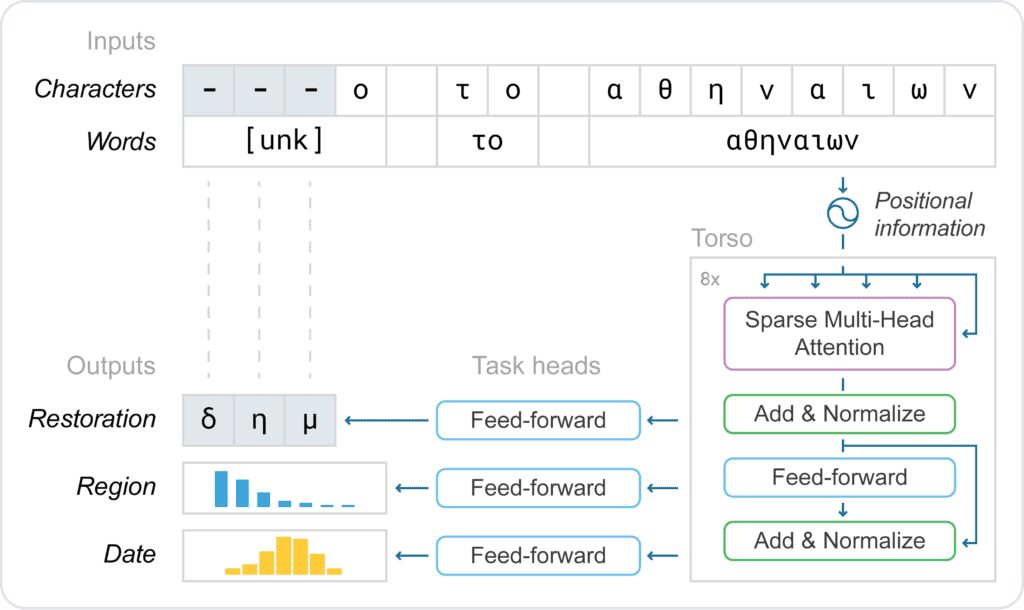
Les trois premiers caractères de cette inscription manquent.
Ithaca propose de lire : « δήμο το αθηναίων » (« le peuple d’Athènes »). Et des hypothèses sur la région et la date. Crédit : DeepMind/Ithaca.
UN GROS TRAVAIL DE NETTOYAGE DU JEU DE DONNÉES
Pour entraîner leur modèle, les chercheurs ont utilisé des inscriptions en grec ancien écrites entre le septième siècle avant J.-C. et le cinquième siècle de notre ère. Un choix dicté par la disponibilité de corpus numérisés et par leur variabilité en termes de contenu et de contexte. Leur jeu de données initial réunissait des textes retranscrits de 178 551 inscriptions du Packard Humanities Institute, provenant de 84 régions. Il a fallu un gros travail de « nettoyage » de cette ancienne base de données pour la rendre exploitable. Ils ont établi des règles d’annotation des caractères manquants comme le font les épigraphistes à la main, à partir de considérations grammaticales et syntaxiques ou de la forme physique du texte, mais aussi avec des interprétations sur les lettres majuscules, la ponctuation, la division des mots, etc.
Décrypter le texte permet également de formuler des hypothèses sur son origine et son époque, à partir d’éléments déterminants comme la grammaire utilisée, un personnage mentionné ou le cas échéant, des indications chronologiques interprétables. Les chercheurs ont ainsi étiqueté chaque inscription avec des métadonnées relatives au lieu et à l’époque de l’écriture. Ils ont finalement retenu 78 608 inscriptions issues du Packard Humanities Institute. Selon eux, c’est le plus grand jeu de données de texte épigraphique exploitable par l’IA.
BERT APPREND À DEVINER LES MOTS MANQUANTS
Le réseau de neurones profonds qu’ils ont choisi de faire tourner est un transformer (c’était déjà le cas de Pythia). « Ces modèles ne sont pas nouveaux », précise François Yvon. Directeur de recherche CNRS et responsable de l’activité traduction au Laboratoire Interdisciplinaire des Sciences du Numérique (LISN, CNRS et université Paris-Saclay), il vient de publier un article sur le modèle transformer. « Aujourd’hui, tout le monde utilise des modèles du type transformer pour l’analyse de textes comme d’images ou de vidéos », précise-t-il. Ithaca s’appuie plus précisément sur l’architecture BERT (Bidirectional Encoder Representations from Transformers).
« BERT est entraîné par auto-apprentissage à prédire des mots masqués en découvrant leurs relations avec le contexte, explique François Yvon. Il transforme chaque mot en vecteur de grande dimension, une représentation qui permet ensuite de le rapprocher de synonymes, de prédire des mots cachés. Rien d’étonnant donc à ce que ce soit très efficace dans cette application où l’on cherche précisément à reconstruire des mots ou des fragments de mots manquants. J’ai en revanche été surpris par la petite taille de la base de données d’entraînement, car les architectures BERT sont habituellement entraînées sur des millions de phrases. Pour contourner cette limitation, les auteurs se sont appuyés sur des méthodes originales d’augmentation de données qui consistent à produire automatiquement des variantes des données disponibles pour en accroître le nombre et la diversité. »
UNE RECHERCHE COLLABORATIVE RICHE ET ÉVOLUTIVE
Ithaca fournit des prédictions intelligibles et multiples, en l’occurrence plusieurs hypothèses classées par probabilités. Plus précisément, une liste des vingt prédictions les plus probables pour la restauration du texte, un classement parmi les 84 régions méditerranéennes pour son origine, et des intervalles de dates plus ou moins précis. Aux historiens de prendre la décision finale.
Ithaca est un bel exemple de recherche collaborative et les chercheurs ont d’ailleurs évalué ce qu’elle apporte aux hommes de l’art. Selon eux, les épigraphistes seuls déchiffrent correctement 25% des passages manquants, Ithaca seule en déchiffre 62% alors que l’association de l’IA et des épigraphistes permet d’atteindre une efficacité de 72%. En outre, cet outil apporte une contribution de plus aux débats d’historiens, comme les chercheurs ont pu le vérifier en datant un groupe d’inscriptions concernant des décrets fondamentaux pour l’histoire politique d’Athènes. La controverse porte sur la date de ces décrets : antérieurs ou postérieurs à 446-445 av. J.-C. ? Ithaca prédit une date moyenne pour tous ces décrets autour de 421 av. J.-C., conformément aux conclusions des travaux les plus récents.
Ithaca est disponible en open-source. Il pourrait être adapté et enrichi pour se rendre utile dans toutes les disciplines traitant de textes anciens (papyrologie, numismatique, étude de codex…), dans toute langue (ancienne ou moderne), et en intégrant également de nouvelles métadonnées comme des images ou des annotations stylistiques.
Isabelle Bellin
Image en une : Cette inscription restaurée énonce un décret concernant l’Acropole d’Athènes. Elle date de 485/4 av. J.-C. (CC BY-SA 3.0, WikiMedia)
1. Yannis Assael, Thea Sommerschield, Brendan Shillingford et al. Restoring and attributing ancient texts using deep neural networks. Nature 2022. doi.org





