
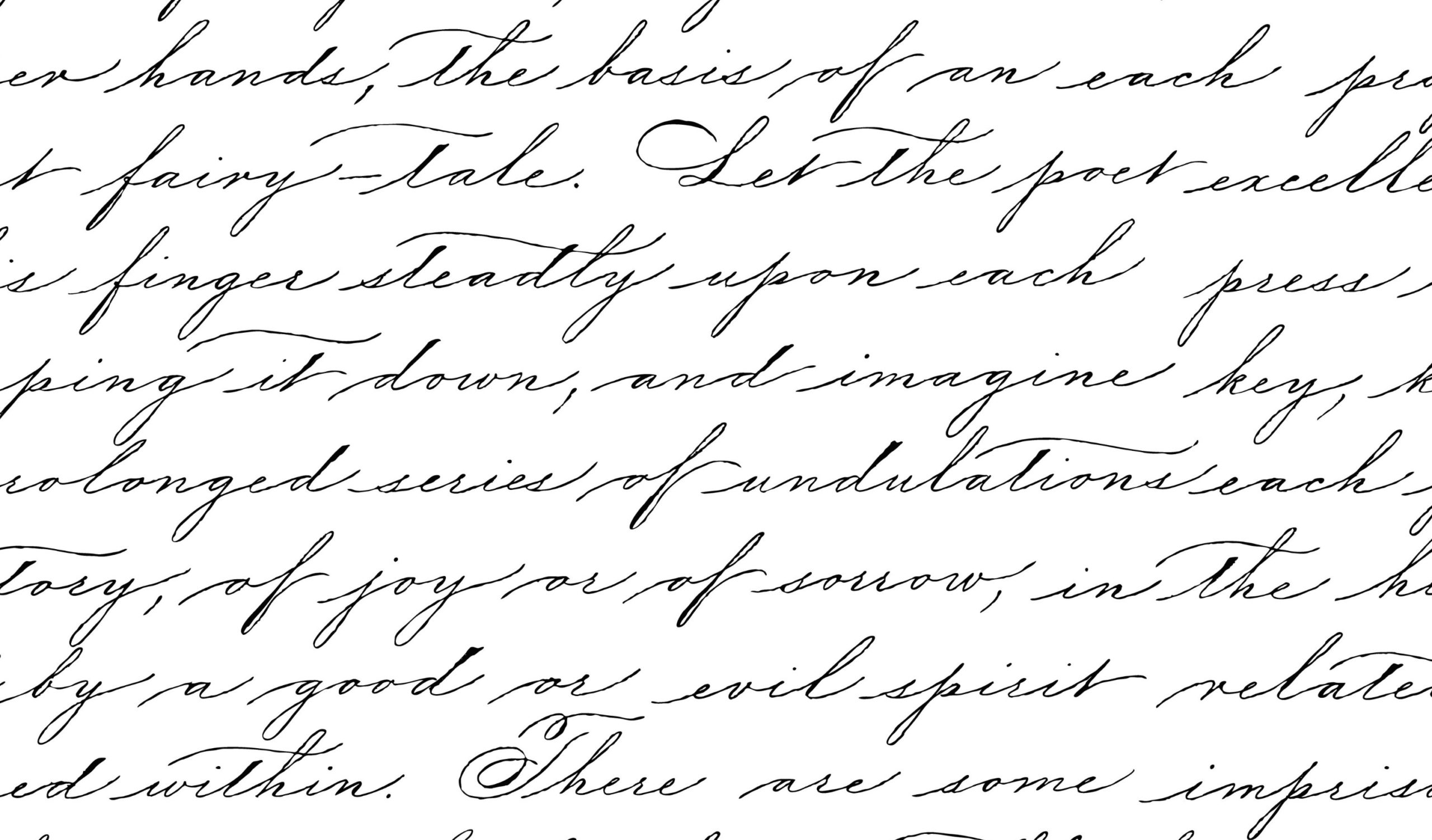
La reconnaissance d’écriture manuscrite : de nouvelles applications pour un des plus vieux problèmes d’IA
⏱ 9 minChristopher Kermorvant (CEO de Teklia) kermorvant@teklia.com
La reconnaissance d’écriture manuscrite est l’un des plus vieux problèmes qui ait été posé à l’intelligence artificielle, depuis son avènement dans les années 1950. Terrain de jeu incontournable des nouveaux algorithmes d’apprentissage, elle reste un véritable défi scientifique et technique.
Reconnaître et comprendre une écriture met en jeux toutes les composantes de l’intelligence artificielle (IA) : il faut visualiser une image et détecter le texte (ce qui suppose de disposer de méthodes de perception visuelle), suivre le tracé de l’écriture (via un planning et le suivi d’une séquence d’actions) puis reconnaître les caractères (grâce à des algorithmes de reconnaissance de formes) et enfin reconnaître les mots et les phrases (par le traitement automatique de la langue) pour aller jusqu’à les comprendre (via une modélisation sémantique). C’est sans doute pour cette raison que la reconnaissance d’écriture partage avec la reconnaissance de la parole et la traduction automatique le privilège d’être parmi les plus anciens problèmes d’IA.
La drosophile des chercheurs en IA
Dans la plupart des cas simples, les performances des systèmes de reconnaissance d’écriture sont aujourd’hui comparables à celles de l’humain, voire les dépassent, du moins pour les tâches les plus proches de la perception (détection du texte, suivi, reconnaissance des caractères et des mots). Pourtant, cela reste un véritable terrain d’expérimentation. La reconnaissance d’écriture manuscrite est même souvent considérée comme la drosophile des chercheurs en IA. Pour preuve, la plupart des nouveaux algorithmes d’apprentissage continuent d’être testés sur le jeu de données MNIST (Modified National Institute of Standards and Technology). Créée en 1998, cette base comporte 60 000 images de chiffres manuscrits pour entraîner les systèmes et 10 000 images pour les tester (voir ci-dessous) [LeCun, 1998]. Les algorithmes doivent montrer leurs performances sur cette base avant de s’attaquer à des problèmes plus complexes. Aujourd’hui, les meilleurs algorithmes prédisent la bonne réponse dans 99,97% des cas sur cette base.

S’évaluer sur la base de données de chiffres manuscrits MNIST reste souvent un passage obligé pour les nouveaux algorithmes d’apprentissage.
Dès lors, de nombreux chercheurs considèrent que le problème de la reconnaissance d’écriture, même manuscrite, est un problème résolu. D’autant plus que des systèmes de reconnaissance d’écriture imprimée sont désormais disponibles dans tous les scanners et téléphones portables. Ils permettent de reconnaître, quasiment sans faute, un texte imprimé. À condition toutefois qu’il soit de bonne qualité, sur papier blanc, sans trop d’effet de perspective et avec une bonne lumière. Mais ces très bons résultats de reconnaissance pour l’écriture imprimée « propre » ne sont pas généralisables, notamment à l’écriture manuscrite.
De l’écriture imprimée propre au manuscrit libre
Certaines écritures restent difficiles à déchiffrer par un algorithme, voire par un humain, à l’instar des écritures de médecins, même si la tâche ne doit pas être si complexe pour une machine, puisque tout pharmacien arrive à délivrer les bons médicaments avec la bonne posologie à la lecture d’une ordonnance manuscrite. De même, les écritures arabes ou chinoises semblent poser des problèmes de reconnaissance très complexes… pour des Européens. Tout comme les écritures d’archives et historiques, car à la complexité d’une écriture que seuls les paléographes peuvent déchiffrer, s’ajoute la compréhension d’une langue qui n’est plus parlée ou qui a évolué. Pourtant toutes ces écritures ont été produites par des hommes avec l’objectif de se faire comprendre sans erreur par d’autres hommes. Une tâche qui devrait donc être à la portée d’une IA. Il reste donc encore de beaux défis. Et ce ne sont pas les seuls.
Remontons d’abord le fil de l’histoire. Depuis ses débuts dans les années 1950 et jusqu’aux années 1990, la reconnaissance d’écriture nécessitait de mettre en œuvre un grand nombre de techniques de traitement d’images et de reconnaissance de formes. De fait, la mise au point d’un système standard supposait le développement de nombreux modules : pour le débruitage de l’image, l’extraction de caractéristiques et la classification des formes. À cette époque, les capteurs étaient moins performants et les images de plus faible résolution qu’aujourd’hui.
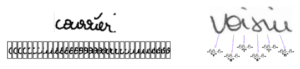
De nombreuses étapes de prétraitement des images étaient nécessaires pour normaliser l’écriture : filtrage et suppression du bruit de fond (par exemple quadrillage, tâches, marques dues au vieillissement du support), conversion en image binaire, détection des traits, reconstitution du tracé, découpage en mots et en caractères (voir ci-dessous). Une fois ces prétraitements effectués, des caractéristiques (features) étaient calculées sur les éléments constitutifs de l’écriture au niveau du trait, du caractère ou du mot. Puis des algorithmes de reconnaissance des formes permettaient de classifier chacun des éléments constitutifs de l’écriture, souvent par des techniques simples comme les algorithmes des plus proches voisins ou des perceptrons (les premiers réseaux de neurones).

Reconnaissance d’écriture par segmentation explicite : à gauche, les lignes sont découpées en mots, puis les mots en graphèmes (parties de caractères) ; à droite des vecteurs de caractéristiques sont calculés sur les éléments segmentés (histogrammes de profils, histogrammes de gradients orientés, densité de pixels par zone).
Des modèles statistiques aux réseaux de neurones
À partir des années 1990, les systèmes de reconnaissance ont commencé à utiliser des modèles statistiques de type modèles de Markov cachés (HMM pour Hidden Markov Model), très similaires à ceux utilisés pour la reconnaissance de la parole. Grâce à leur entraînement sur des grandes bases de données, ces systèmes statistiques étaient plus robustes aux bruits et aux variations que les systèmes précédents, si bien que les techniques de prétraitement ont pu être simplifiées. De plus, avec ces modèles, la segmentation en mots, caractères ou traits n’était plus nécessaire et on pouvait utiliser une segmentation par fenêtre glissante, plus simple et plus robuste (voir ci-dessous). Enfin, des statistiques linguistiques pouvaient être incorporées dans les systèmes grâce à des modèles de langue. La mise au point de ces systèmes restait cependant complexe et spécifique à un script et à une langue.
Segmentation d’un mot par fenêtre glissante (à gauche) et modélisation d’un mot par des HMM de lettres (à droite)
À partir de la fin des années 2000, la reconnaissance d’écriture a peut-être été le premier domaine à être profondément transformé par le renouveau des réseaux de neurones. Dès 2009, lors de plusieurs évaluations internationales, on pouvait constater que les premiers systèmes complètement neuronaux, combinant une extraction de caractéristiques par des réseaux à convolution et une modélisation des séquences de caractères par des réseaux récurrents [Graves2009], dépassaient largement les performances des systèmes statistiques à l’état de l’art [Bluche, 2014 ; Moysset, 2014].
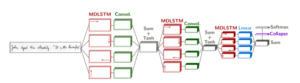
Un réseau de neurones profond pour la reconnaissance d’écriture manuscrite, combinant des réseaux récurrents multidimensionnels (MDLSTM) et des réseaux à convolution (Convol.) (d’après [Bluche, 2016])
Désormais, la position des réseaux de neurones est hégémonique dans les systèmes de reconnaissance de l’écriture alors que le domaine avait toujours connu une grande diversité d’approches. Il n’y a quasiment plus de prétraitements et les modules d’extraction de caractéristiques, de classification et de modélisation des séquences, tous basés sur des réseaux de neurones, sont entraînés simultanément. De plus, les systèmes ne sont plus spécifiques à un script ou une langue ; une même architecture peut être utilisée pour le français, l’arabe ou le chinois : il suffit de changer la base d’entraînement.
Vers une reconnaissance d’écriture adaptative…
Historiquement, les principaux domaines d’application de la reconnaissance d’écriture étaient ceux pour lesquels un grand nombre de documents manuscrits devait être traité rapidement, à savoir le tri postal [Gilloux, 1993] et la reconnaissance de chèques [Gorski, 1999]. Les performances des systèmes de lecture automatique pour ces deux applications sont aujourd’hui supérieures aux performances humaines car les textes sont très contraints. À partir des années 2000, de tels systèmes ont été utilisés sur des documents plus complexes, par exemple pour traiter le courrier entrant dans des grandes organisations [Grosicki, 2009, Brunessaux, 2014], pour l’indexation de notes personnelles manuscrites [LabcomINKS, 2016] ou pour l’indexation de documents d’archives historiques [Bluche, 2017].
Aujourd’hui, grâce à d’importants programmes de numérisation, les bibliothèques et les services d’archives à travers le monde ont mis à disposition des millions de documents manuscrits. De plus, l’adoption par un nombre croissant d’institutions patrimoniales du protocole IIIF (International Image Interoperability Framework), a ouvert la possibilité de traiter de grandes collections d’images sur des plateformes de service dans le cloud grâce à un accès standardisé aux images de leurs collections sur le web [Boros, 2019]. La demande des utilisateurs est désormais de pouvoir y faire des recherches dans leur contenu textuel, comme on le fait couramment sur les pages web. Cependant, une certaine expertise est encore nécessaire pour adapter et appliquer les systèmes de reconnaissance d’écriture.
Enfin, alors que les performances des systèmes en laboratoire sont désormais supérieures aux performances d’un humain sur des écritures difficiles à déchiffrer, l’enjeu de la reconnaissance d’écriture manuscrite se situe désormais dans le passage à l’échelle : savoir traiter des millions de documents et des écritures très diverses, sans avoir à chaque fois à intervenir pour réentraîner les systèmes. Il faut, pour cela, développer des techniques basées sur de l’apprentissage semi-supervisé–à partir de données étiquetées et non étiquetées – pour l’adaptation automatique des systèmes de reconnaissance à des écritures nouvelles ou qui évoluent dans le temps, sans avoir besoin de grandes bases de données annotées et de l’intervention d’un ingénieur pour contrôler l’apprentissage. Une vraie technologie de reconnaissance d’écriture adaptative.
et des traitements automatiques
Dans ce contexte, Teklia développe une plateforme de traitement automatique des documents d’archives et historiques à base de deep learning : nous utilisons des réseaux de neurones profonds tant pour la classification que l’analyse de la structure, la reconnaissance d’écriture manuscrite et imprimée, l’extraction d’information ou l’indexation. La plateforme de Teklia permet de conduire un projet de traitement automatique d’un fonds d’archives dans sa totalité, de la spécification au suivi de la production en passant par l’annotation pour l’entraînement des systèmes et la validation humaine si nécessaire. Les modèles sont adaptés à chaque projet, ce qui permet d’atteindre des performances bien supérieures aux modèles génériques fournis par les grandes plateformes (Google, Microsoft, Amazon). Ci-dessous quelques exemples d’applications de nos projets.

Extraction automatique des informations généalogiques dans les registres paroissiaux du Québec (Projet E-Balsac). http://balsac.uqac.ca/
Indexation automatique des registres de la chancellerie royale (1300-1380) et des chartes européennes (Projet HIMANIS/HOME). https://www.himanis.org/

Extraction d’information dans les collections des muséums d’histoire naturelle européens (Projet SYNTHETIS+). https://www.synthesys.info/
Reconnaissance et structuration des livres d’heures médiévaux (Projet HORAE). https://horae.digital/
* [Bluche, 2014] T. Bluche, J. Louradour, M. Knibbe, B. Moysset, M. F. Benzeghiba, and C. Kermorvant, « The A2iA Handwritten Arabic Text Recognition System at the OpenHaRT2013 Evaluation Campaign, » in Document Analysis Systems,2014.
* [Bluche2016] T. Bluche, “Joint line segmentation and transcription for end-to-end handwritten paragraph recognition,” in Advances in Neural Information Processing Systems, 2016, pp. 838–846.
* [Bluche,2017] T. Bluche, S. Hamel; C. kermorvant, J. Puigcerver, D. Stutzmann, A. Toselli et E. Vidal , “Preparatory KWS Experiments for Large-Scale Indexing of a Vast Medieval Manuscript Collection in the HIMANIS Project,” in International Conference on Document Analysis and Recognition,2017.
* E. Boros, A. Toumi, E. Rouchet, B. Abadie, D. Stutzmann, C. Kermorvant, « Automatic page classification in a large collection of manuscripts based on the International Image Interoperability Framework » in International Conference on Document Analysis and Recognition,2019.
* [Brunessaux, 2014] S. Brunessaux et al., “The Maurdor project : Improving automatic processing of digital documents,” in Document Analysis Systems, 2014.
* [Gilloux, 1993] M. Gilloux, “Research into the new generation of character and mailing address recognition systems at the French post office research center,” Pattern Recognition Letters,1993.
* [Gorski, 1999] N. Gorski, V. Anisimov, E. Augustin, O. Baret, D. Price, et J. C. Simon, “A2iA Check Reader: a family of bank check recognition systems,” in International Conference on Document Analysis and Recognition,1999.
* [Graves, 2009] A. Graves et J. Schmidhuber, « Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks », NIPS, 2009
* [ Grosicki, 2009] E. Grosicki, M. Carré, J.-M. Brodin, and E. Geoffrois, “Results of the second RIMES evaluation campaign for handwritten mail processing,” in Proceedings of the International Conference on Document Analysis and Recognition, 2009.
* [Kermorvant, 2010] C. Kermorvant and J. Louradour, “Handwritten mail classification experiments with the Rimes database,” in Proc. of the Int. Conf. on Frontiers in Handwriting Recognition, 2010.
* [LabcomINKS, 2016] https://anr.fr/Project-ANR-16-LCV2-0004
* [LeCun, 1998] Y. LeCun, L. Bottou, Y. Bengio, et P. Haffner, “Gradient-Based Learning Applied to Document Recognition,” Proc. IEEE,1998.
* [Moysset, 2014] B. Moysset, T. Bluche, M. Knibbe, M. F. Benzeghiba, R. Messina, J. Louradour et C. Kermorvant, “The A2iA Multi-lingual Text Recognition System at the Maurdor Evaluation,” in International Conference on Frontiers in Handwriting Recognition,2014.
* [Sanchez, 2016] J. A. Sánchez, V. Romero, A. H. Toselli, and E. Vidal, “ICFHR2016 Competition on Handwritten Text Recognition on the READ Dataset,” in International Conference on Frontiers in Handwriting Recognition,2016.





