

Le méta-apprentissage fait ses premiers pas en robotique
⏱ 4 minDes modèles capables d’apprendre à apprendre… mieux, plus vite, au moins dans un certain domaine, c’est ce que vise le méta-apprentissage, qui connait un regain d’intérêt ces dernières années. Après la sphère des images et celle du langage, il fait aussi ses premiers pas en robotique.
« Le méta-apprentissage (meta-learning) est un concept assez ancien, explique Jean-Baptiste Mouret, spécialiste de la robotique résiliente et directeur de recherche Inria au sein de l’équipe Larsen (Inria Nancy et Loria). Toutefois, jusqu’à récemment, les solutions proposées ne donnaient pas de résultats très probants, notamment parce qu’elles nécessitaient d’énormes puissances de calcul. Pourtant, cette démarche répond à un besoin omniprésent en robotique. » Pour qu’un robot un tant soit peu versatile soit utile, il faut qu’il apprenne quantité de gestes, de démarches, de solutions pour accomplir les tâches qui lui sont confiées. Et il n’est pas souhaitable qu’il apprenne, par exemple, à saisir chaque objet qu’il devra manipuler à partir de zéro.
Les robots apprennent… à coups de récompenses ou de punitions
« En robotique, explique Olivier Sigaud, professeur à Sorbonne Université et chercheur au sein de l’équipe Amac (Architectures et Modèles pour l’Adaptation et la Cognition) de l’Isir (Institut des Systèmes Intelligents et de Robotique), nous utilisons surtout l’apprentissage par renforcement (Reinforcement Learning ou RL), qui se distingue de l’apprentissage plus ou moins supervisé, très utilisé en vision. »
Un robot apprend à exécuter une tâche, physiquement ou par simulation, en améliorant progressivement, par essais et erreurs, une fonction qui associe à l’état courant la prochaine action à exécuter. À chaque étape, une valeur numérique, qui peut être interprétée comme une récompense (ou une punition), est calculée et retournée à l’algorithme, qui met à jour le modèle, de manière à maximiser cette récompense (ou minimiser cette punition). C’est donc surtout au « méta-apprentissage par renforcement » (Meta Reinforcement Learning ou metaRL) que s’intéresse la robotique.
Préparer le robot à réagir à une situation nouvelle
« Le méta-apprentissage offre des perspectives intéressantes, estime Jean-Baptiste Mouret, tout particulièrement dans le cas de robots mobiles qui peuvent rencontrer dans le monde réel des aléas qui les placent dans des situations nouvelles, auxquelles ils doivent s’adapter au plus vite. Ils peuvent de plus être l’objet de pannes, au niveau des effecteurs (moteur déficient, articulation bloquée, patte cassée…) ou des capteurs (erreur dans les mesures d’orientation par exemple). Il est donc souhaitable qu’ils soient capables d’apprendre rapidement, à partir d’un petit nombre d’essais sur le terrain, une nouvelle manière d’avancer vers l’objectif, adaptée à la nouvelle situation. Pour cela, une phase de méta-apprentissage par renforcement est donc une façon de les préparer à réagir efficacement devant une nouvelle situation en les dotant d’un modèle capable d’apprendre vite sur le terrain. »
« Depuis quelques années, nous assistons à une floraison de publications prometteuses sur le méta-apprentissage, indique Jean-Baptiste Mouret. En particulier, l’approche MAML¹, proposée par Chelsea Finn en 2017, constitue un progrès notable. MAML cherche un jeu de poids « magique« pour le réseau de neurones considéré, un point de départ à partir duquel il apprendra une nouvelle tâche plus vite qu’en partant d’un jeu de paramètres aléatoire. Une sorte de « Place de l’Étoile« , très centrale, à partir de laquelle on arrive en général plus vite à destination. Nous nous sommes intéressés à MAML. Les résultats sont intéressants, mais l’inconvénient de cette approche est qu’elle cherche et fournit une seule « Place de l’Étoile« , un seul point de départ pour apprendre à s’adapter à une nouvelle situation. Notre équipe a cherché à corriger cet inconvénient et nous avons conçu et publié² un nouvel algorithme de meta-learning, que nous appelons FAMLE (Fast Adaptation through Meta-Learning Embeddings), et qui produit plusieurs jeux de données de départ, chacun adapté à une situation particulière. »
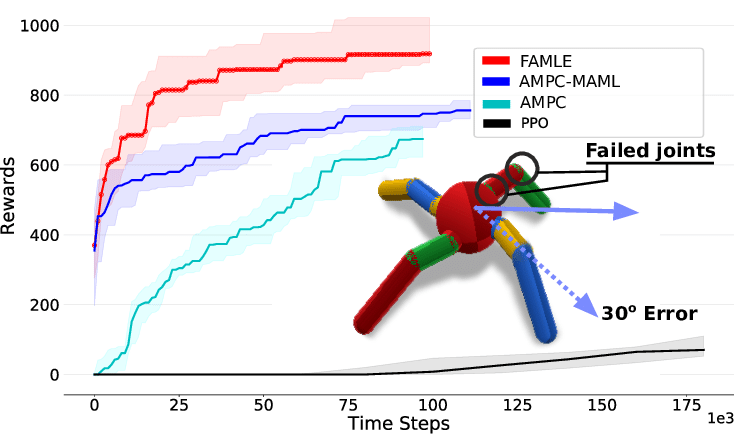
L’algorithme FAMLE, testé par ses inventeurs, permet à ce robot simulé d’apprendre à marcher droit, malgré diverses pannes sur ses articulations et son capteur d’orientation, plus vite qu’avec MAML, et surtout bien plus vite que sans méta-apprentissage (AMPC).
Des solutions exigeantes en puissance de calcul
« Après MAML, ajoute Olivier Sigaud, des centaines de publications ont proposé des extensions ou variations sur ce thème, comme Reptile³, par exemple. D’autres encore ont emprunté des voies différentes. Et des stratégies de méta-apprentissage dédiées au contexte de l’apprentissage par renforcement ont même été publiées. En 2019, notamment, un article⁴ cosigné par Chelsea Finn, a proposé un algorithme de « metaRL« , dénommé PEARL (Probabilistic Embeddings for Actor-critic RL). Dans l’ensemble, pourtant, les solutions proposées restent très exigeantes en puissance de calcul, et fournissent des résultats satisfaisants surtout lorsque les tâches considérées sont assez proches les unes des autres. Comme apprendre à saisir une série d’objets différents. »
L’alternative de l’apprentissage multitâche
« Mais d’autres approches répondent d’une autre manière au besoin d’entraîner économiquement les robots à un grand nombre de tâches distinctes, estime Olivier Sigaud. Ainsi, l’apprentissage multitâche (Multi-task learning), qui fait l’objet de recherches depuis une vingtaine d’années, nous semble très prometteur. Il consiste à entraîner un modèle à résoudre en même temps un ensemble prédéterminé de tâches proches. Des solutions de ce type, bien plus efficaces que le méta-apprentissage, sont déjà disponibles. Nous avons d’ailleurs publié⁵ en 2019 avec des chercheurs de l’équipe Flowers (Inria Bordeaux) une contribution dans ce domaine. Notre algorithme s’appelle Curious, pour « Continual Universal Reinforcement learning with Intrinsically mOtivated sUbstitutionS » ».
« Le méta-apprentissage est une des façons d’aborder le problème général de l’efficacité de l’apprentissage et de la généralisation, confirme Stéphane Doncieux, le directeur adjoint de l’Isir. Le but est d’apprendre vite, ce qui peut se faire en changeant l’ordre dans lequel on va apprendre un modèle, c’est le principe du « curriculum learning« . L’homme, comme l’animal, acquiert des compétences en respectant une certaine progression, en suivant un parcours. » Apprendre à ramper prépare à la marche, qui prépare à la course et à l’escalade. « Le curriculum learning repose sur cette idée, poursuit le chercheur. L’apprentissage par transfert (transfer learning) est aussi une façon d’apprendre plus vite en s’appuyant sur des compétences apprises précédemment, autrement dit de ne pas repartir de zéro à chaque fois que l’on veut apprendre quelque chose. Le méta-apprentissage est une façon d’intégrer ces deux dimensions dans l’apprentissage. »
Pierre Vandeginste
1. Chelsea Finn et al., “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”, ICML 2017. arxiv.org
2. Rituraj Kaushik, Timothée Anne & Jean-Baptiste Mouret, “Fast Online Adaptation in Robotics through Meta-Learning Embeddings of Simulated Priors”, IEEE International Workshop on Intelligent Robots and Systems (IROS) 2020. hal.inria.fr
3. Alex Nichol et al., “On First-Order Meta-Learning Algorithms”, 2018. arxiv.org
4. Kate Rakelly et al, “Efficient Off-Policy Meta-RL via Probabilistic Context Variables”, International Conference on Machine Learning (ICML) 2019. arxiv.org
5. Cédric Colas et al., “CURIOUS: Intrinsically Motivated Modular Multi-Goal Reinforcement Learning”, International Conference on Machine Learning (ICML) 2019. arxiv.org
