
Clustering
Clustering (ou partitionnement des données) : Cette méthode de classification non supervisée rassemble un ensemble d’algorithmes d’apprentissage dont le but est de regrouper entre elles des données non étiquetées présentant des propriétés similaires. Isoler ainsi des schémas ou des familles permet aussi de préparer le terrain pour l’application ultérieure d’algorithmes d’apprentissage supervisé (comme le KNN).
Le clustering est utilisé notamment lorsqu’il est coûteux d’étiqueter le données. C’est néanmoins un problème mal défini mathématiquement : différentes métriques et/ou différentes représentations des données aboutiront à différents regroupements sans qu’aucun ne soit nécessairement meilleur qu’un autre. Ainsi la méthode de clustering doit être choisie avec soin en fonction du résultat attendu et de l’utilisation prévue des données.
Les algorithmes de clustering les plus courants sont le K-Means, les algorithmes de maximisation de l’espérance (de type EM, comme les mixtures gaussiennes) et les partitions de graphes. Voyons comment cela se traduit dans deux exemples :
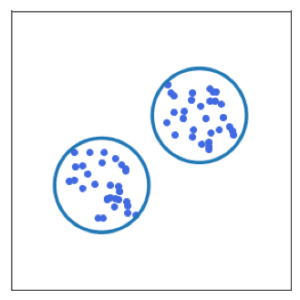
Ici, les données peuvent être aisément regroupées en deux groupes (dans 2 cercles). L’algorithme K-Means (ou partitionnement en k-moyennes) qui consiste à diviser les points en k groupes appelés clusters, permet d’obtenir ce résultat rapidement et efficacement.

Dans cet autre exemple (le cas des « 2 lunes »), un clustering « naturel » serait de regrouper les données en 2 lunes. L’algorithme K-means ne permet pas de produire ce regroupement. Par contre, les algorithmes de partition de graphes peuvent y parvenir.
+ Retour à l'index