
Catastrophes naturelles : la data science intéresse les assureurs… et les assurés
Le secteur de l’assurance compte sur la science des données pour prédire les conséquences de catastrophes naturelles avant leur survenue : volume de déclarations de sinistres à traiter, budget à provisionner, nombre de sinistrés à accueillir en agence, etc. Un jour, leurs modèles prédictifs pourraient aussi limiter les dégâts.
Tempête, inondation, cyclone… Quand une catastrophe naturelle s’abat sur un territoire, les assureurs activent immédiatement leurs cellules de gestion de crise. Principal objectif : traiter au plus vite l’arrivée en masse de demandes d’indemnisations. Grâce à la data science, ils veulent aller plus loin. L’idée ? Réussir à optimiser ces dispositifs de gestion de crise avant même que les zones à risque ne soient encore touchées.
La Maif développe par exemple un outil capable de prédire le nombre de déclarations de sinistres par ses assurés sur telle ou telle zone, avant même que ne s’y abatte une tempête hivernale ou une inondation cévenole. Calibré sur la sinistralité d’événements climatiques passés les plus significatifs (tempêtes Klaus, Xynthia, Joachim…), leur modèle de prévision utilise trois sources de données : météorologiques, des données sur les communes et sur les assurés Maif.
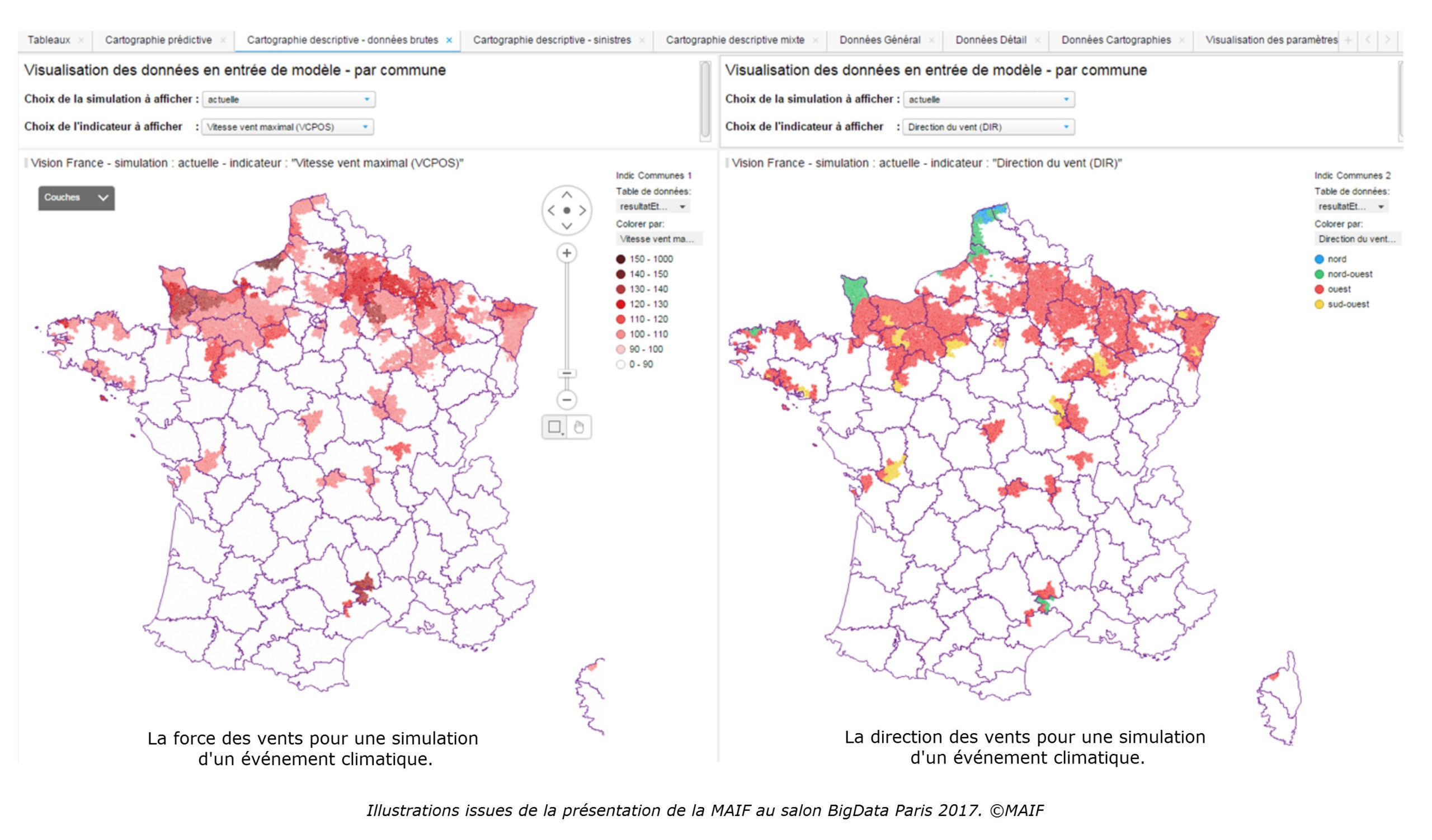
Visualiser les sinistres en vue
« Écrit en langage R, on le lance et on l’utilise via une seule et unique interface de data visualisation nommée Tibco Spotfire, indique Orlane Monnet du département Etudes statistiques de la Maif. Cette dernière permet de visualiser le nombre de déclarations de sinistres prévisibles sur une carte de France avec les zones qui devraient être les plus touchées. » Par simple clic sur des curseurs, on peut même faire varier la force des rafales et visualiser en direct l’impact en nombre de sinistres. La Maif a commencé à tester son outil fin 2016 sur des inondations, puis sur de petites tempêtes début 2017.
À l’avenir, ce type de modèles pourrait encore être affiné pour mieux anticiper les coûts attendus, et surtout alerter les assurés par SMS ou mails de l’imminence possible d’une catastrophe naturelle, leur prodiguer des conseils, commencer à mobiliser les entreprises de réparation, etc. Toutefois, cela nécessiterait des données plus précises sur les assurés : à quel étage de l’immeuble est situé le logement, y a t’il des arbres sur le terrain, quel est type de toiture, nature des composants du bâti, y a-t-il une cave, un sous-sol, un parking souterrain, une piscine, le terrain est-il en forte ou faible pente, etc. Autant de données lourdes à collecter, et que les assurés ne sont pas forcément enclins à livrer…
Exploiter les bases de données
Plus largement, pour développer de nouveaux outils de data science, les assureurs disposent de bases de données leur permettant de rapprocher les catastrophes naturelles passées avec le montant des dommages causés (comme les bases E-Risk et SILEHC). Pour valoriser ces bases de données, les outils SQL atteignent souvent leurs limites en termes de temps de calcul : on recourt de plus en plus à des outils NoSQL et de big data.
On trouve des modèles déterministes, des modèles multicritères, les modèles « CatNat » spécifiques aux catastrophe naturelles construits par des sociétés privées à partir de variables aléatoires… ou bien encore des méthodes d’analyse multivariée et de classification supervisée ou non supervisée (text mining, analyse des données en composantes principales (ACP), des correspondances multiples (ACM)…). Quant aux systèmes d’information géographique (SIG), ils permettent de spatialiser les dommages et les phénomènes. Ce qui laisse espérer des moyens de prédiction de plus en plus performants comme le résume Stéphane Renoux du Programme Data & I.A à la Maif : « L’usage d’algorithmes de machine learning et de clustering peut sans doute nous apprendre beaucoup des risques possibles sur les biens de nos sociétaires, en allant chercher des corrélations que nous ne soupçonnons pas ! »
Jean-Philippe BRALY






