
Hai : mieux vous connaître pour mieux vous conseiller !
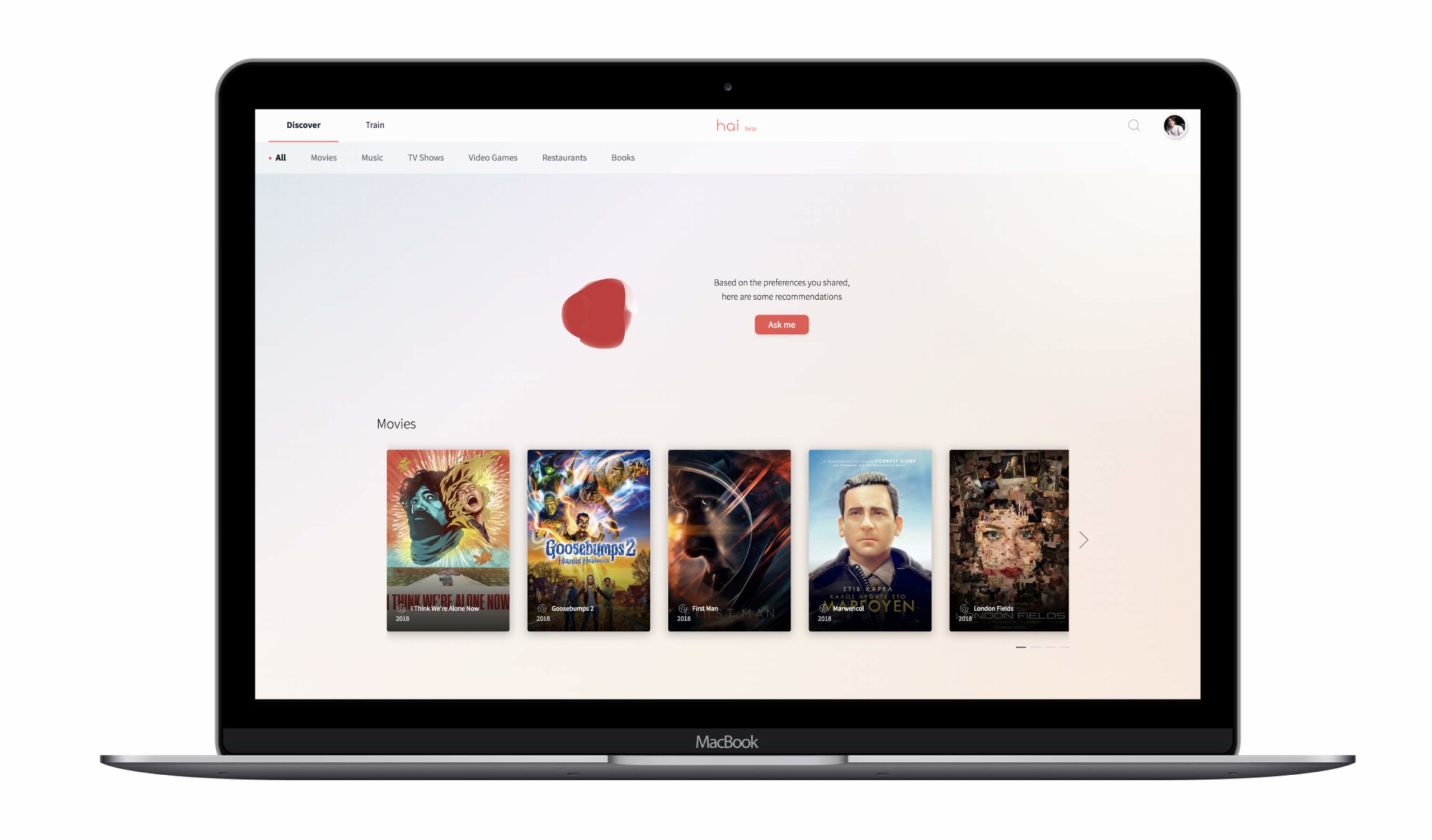
⏱ 5 minHai est un moteur de recommandation à base d’intelligence artificielle pour vous conseiller des films, des musiques, des livres et des restaurants qui correspondent vraiment à vos goûts. Développé par la start-up Crossing Minds, il est disponible depuis le mois dernier sous forme d’application mobile. Et bientôt sous celle de site web.
L’idée de base de ce nouveau moteur de recommandation est aussi simple que puissante : croiser tous vos goûts pour mieux vous connaître et vous recommander des choix selon votre personnalité, comme le ferait un ami. « Pourquoi cloisonner et se limiter à des choix musicaux sur la base de vos goûts musicaux, comme le proposent Spotify ou Deezer, des séries identifiées sur la base de vos séries préférées, des livres selon vos achats d’ouvrages »,fait remarquer Emile Contal, CTO de Crossing Minds, jeune pousse créée en 2016 à San Francisco. Il pointe aussi le délai de réponse de ces moteurs sélectifs : les utilisateurs de Netflix passeraient en moyenne 20 minutes par jour pour choisir une série. « Avec notre intelligence artificielle (IA) baptisé Hai, c’est instantané, et on est surpris des choix proposés dès le début, assure-t-il. Notre ambition est que Hai devienne une référence en matière de recommandation de divertissements. »
À partir de quelques lignes de code
Le secret de ses performances, c’est le deep learning, la spécialité des jeunes fondateurs français de Crossing Minds : Emile Contal, CTO, et Alexandre Robicquet, CEO. Leur rencontre date de 2013 : Emile, informaticien, débute alors une thèse à l’ENS Paris-Saclay, au CMLA, associant théorie et application. Il encadre des stagiaires de master, dont Alexandre, auquel il fait découvrir le machine learning, qui devient vite une passion pour ce dernier ! Ils passent ensemble leur été au labo pour peaufiner un article de recherche. Et écouter de la musique, autre passion commune. Ils s’échangent leurs morceaux préférés et se demandent pourquoi les moteurs de recommandation comme Spotify, Deezer, Pandora ou Last.fm ne leur font jamais rien découvrir.
Est-ce si difficile ? Avec un peu de machine learning… Ils essaient, pour voir, de bricoler un petit moteur de recommandation sur une base de données de morceaux de musique en libre accès sur le web. « On a juste écrit une centaine de lignes de code, se rappelle Emile Contal. Et on a été bluffés du résultat ! Avec ce petit moteur, j’ai découvert des groupes que j’écoute encore. » Ils décident de créer un petit site web.
Mais Alexandre part travailler à Los Angeles (à l’UCLA), avant d’aller poursuivre ses recherches à l’université de Stanford, au sud de San Francisco. À distance, pendant trois ans, ils continuent d’améliorer leur solution à leurs moments perdus. Une solution radicalement différente des moteurs de recommandation existants. Leur modèle, à base de deep learning, utilise une approche non-linéaire, là où les autres algorithmes utilisent une approche linéaire, avec une factorisation de matrice. « Nos premiers réseaux de neurones ne comportaient que 2 à 3 couches, ce n’était donc pas, à proprement parler, du deep learning, reconnaît Emile Contal. Toutefois, cela permettait de faire de l’apprentissage sur les données, et d’en améliorer les performances en jouant sur la descente de gradient ou grâce à la régularisation. » Cela leur permet aussi d’agglomérer différentes catégories de données (goûts musicaux, séries TV, livres et films) pour mieux cibler les recommandations quelles qu’elles soient.
Un petit coup de pouce et de hasard
Jusqu’à ce qu’en 2016, Alexandre Robicquet rencontre Sebastian Thrun, alors professeur à Stanford, expert en vision par ordinateur et robotique, directeur du Stanford Artificial Intelligence Laboratory, fondateur du Google X Lab, de la plateforme de cours en ligne Udacity, ou encore de KittyHawk, pour créer des drones taxi avec Larry Page – cofondateur de Google –, un entrepreneur de haut vol. « Il nous a encouragés à nous lancer, reconnaît Emile Contal, pas du tout prêt à créer une entreprise à l’époque. À ce moment-là, je m’apprêtais à poursuivre mon cursus académique avec un post-doctorat à Los Angeles. Ce projet est brusquement tombé à l’eau car ma directrice de thèse a dû déménager. Sebastian nous poussait, Alexandre était partant… je suis allé le rejoindre à Stanford, au cœur de la Silicon Valley, et nous avons lancé Crossing Minds. » Sebastian Thrun en est le conseiller.
Première étape : lever des fonds. « Au cours d’une soirée d’étudiants – auxquelles se joignent souvent des investisseurs à l’affût – on évoque le sujet…», raconte-t-il. Banco : une promesse de 500 000 dollars ! De quoi embaucher immédiatement deux ingénieurs développement pour créer le site web. Le projet devient réalité. À l’été 2017, ce sera 3,5 millions de dollars. « Il nous aurait sûrement fallu quatre ans pour arriver à ce stade en France, au lieu d’un an aux États-Unis », estime-t-il. Il faut dire qu’à l’époque, ils obtenaient déjà des résultats prometteurs. Ils avaient comparé la qualité des prévisions de leur solution à celles du tout dernier modèle de recommandation présenté à la conférence de machine learning NIPS : entraînés sur les données de 80 % de 100 000 utilisateurs et de leurs 100 000 films et séries préférés, les modèles devaient prédire les 20 % restants. Hai affichait 8 % d’erreur sans même avoir été optimisée, contre 27 % pour le meilleur du moment !
Beaucoup de deep learning
Comment fonctionne Hai ? En amont de la recommandation, le moteur extrait l’information à partir d’images et de textes qui reflètent les goûts de l’utilisateur : « Nous avons ajouté des techniques de graph embedding pour exploiter des données sous forme de graphes, des représentations mathématiques qui permettent de relier un film et ses acteurs, un livre et son auteur, explique encore Emile Contal. Nous en tirons des informations sous forme vectorielle par traitement d’images, NLP [traitement du langage naturel], etc. Cela nous permet d’exploiter beaucoup de données associées : prenons l’exemple d’un film, il sera enregistré bien sûr par son identifiant (son titre), mais aussi via les informations contenues dans le résumé du film, la liste des acteurs, etc. Idem pour les séries, les livres ou la musique. » Ils exploitent aussi le principe du Transfer learning, qui permet d’appliquer des connaissances sur un domaine à un autre domaine.
Cette phase d’initialisation, menée à partir d’un choix varié de films connus que le nouvel utilisateur « like » ou pas, prend moins de 2 minutes. Elle est même inutile si on s’inscrit avec un compte Facebook ou Google, qui donnent par exemple accès aux Like et Dislike de la personne ou à ses visionnages récurrents sur YouTube.
La représentation vectorielle est aussi particulièrement efficace pour intégrer à la base de données de recommandations un nouveau film, un nouvel artiste ou auteur, ce que les moteurs actuels ne savent pas traiter. « Avec Hai, on peut le recommander tout de suite aux personnes qui aiment déjà les acteurs, musiciens, auteurs en question, ou le concept de l’œuvre, justifie Emile Contal. De même, sur la base de notre connaissance de la personnalité de l’utilisateur, notre modèle permet de lui recommander un restaurant dont il devrait apprécier l’ambiance musicale, le style culturel, etc. » C’est également la promesse de mettre tout le monde d’accord lors d’un choix à plusieurs, par exemple pour trouver un film ou un restaurant qui convienne à des adultes et des enfants : là où les moteurs actuels utilisent une fonction moyennée, ce qui n’a pas beaucoup de sens, le deep learning devrait permettre de privilégier les interactions entre les personnes.

Crossing Minds compte déjà 8 salariés (dont 3 chercheurs) et recherche toujours des chercheurs/ingénieurs. Les dirigeants prévoient une prochaine levée de fonds début 2019 pour développer des API pour des entreprises comme des chaînes de télévision, Netflix, ou des plateformes de contenus multiples, comme celles des compagnies aériennes qui proposent un vaste agrégat de films, musique, lecture dans les avions. C’est cette activité qui devrait financer les prochains développements de Hai, disponible gratuitement sur l’App store depuis la mi-octobre, sans publicité ni produits sponsorisés, et sans revente des données. Des données dont l’accumulation se traduit visuellement, sous la forme d’un avatar en 3D, qui grandit au fur et à mesure pour montrer à quel point il est entraîné, « alimenté » par les données de l’utilisateur. De même, un site web devrait être en ligne dans quelques semaines, et l’application sous Android dans quelques mois.
Isabelle BELLIN
Pour en savoir plus
Le Techcrunch de Crossing Minds en septembre dernier : https://techcrunch.com/startup-battlefield/company/crossing-minds-hai/





