
Grâce à l’IA, le projet Socface permettra de mieux connaître la population française du XIXe siècle
⏱ 4 minVingt recensements de la population française, couvrant la période 1836-1936, seront accessibles en 2024 aux chercheurs en sciences sociales et au grand public, en ligne. Il faut pour cela relire, grâce à l’IA et notamment à l’apprentissage profond, vingt millions de pages manuscrites…
L’intelligence artificielle trouve progressivement sa place dans la boîte à outils de la recherche scientifique. Après les sciences « dures », elle apporte désormais son concours aux sciences sociales. Le projet Socface en est un exemple intéressant. Il s’agit de numériser un siècle de listes nominatives de recensements anciens de 1836 à 1936, soit quelque vingt millions de pages manuscrites. Une fois numérisées, elles permettront à des chercheurs d’accéder à des données de nature démographique mais aussi sociologique, voire économique. En couvrant une grande partie du XIXe siècle et le début du XXe, elles assurent la soudure avec les recensements plus récents, déjà informatisés. Bien sûr les généalogistes, professionnels ou en herbe, sont également impatients d’avoir accès aux résultats, qui seront d’ailleurs rendus publics sur un site en ligne.
« J’essayais de monter un projet sur ces recensements », explique Christopher Kermorvant, le responsable de l’aspect informatique de cette initiative. Spécialiste de la reconnaissance de l’écriture manuscrite et du traitement de documents anciens, il est président de la société Teklia qu’il a fondée en 2015 pour conseiller, développer des outils et proposer ses services dans ce domaine sur lequel il a d’ailleurs déjà eu l’occasion de s’exprimer ici. Il est également chercheur associé à l’Université de Rouen. « Je travaillais sur les registres paroissiaux du Québec. La problématique est assez proche et il s’agit également de traiter une masse de données conséquente : trois millions de pages. Il se trouve que Lionel Kesztenbaum, directeur de recherche à l’Ined (Institut national d’études démographiques), voulait faire la même chose, mais à la main. Avec l’école d’économie de Paris et le service interministériel des Archives de France (Siaf), nous avons déposé une demande de financement auprès de l’ANR, qui nous a été accordée en juillet 2021.»
LE DIFFICILE TRAITEMENT D’ARCHIVES MANUSCRITES
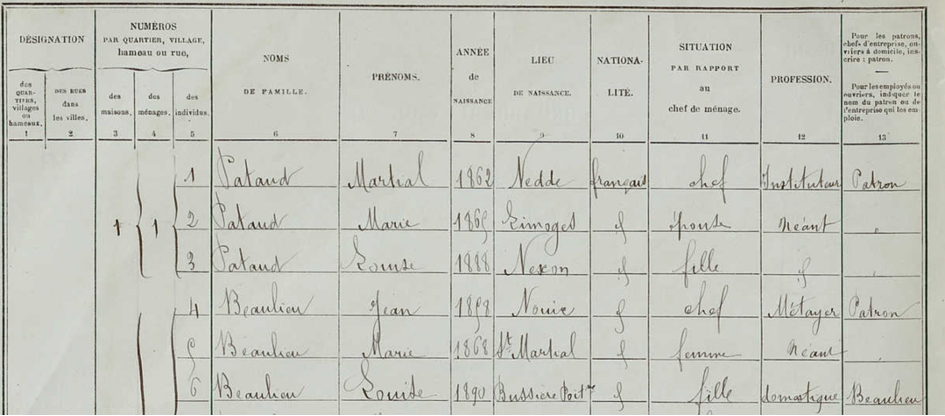
Il s’agit donc de numériser les vingt recensements qui ont eu lieu en France entre 1836 et 1936. La population avoisinant durant cette période les trente millions d’habitants, cela représente quelque six cents millions d’enregistrements concernant chacun un individu. Tout cela étant bien sûr manuscrit. « Nous ne savons pas encore exactement quelle quantité de données, d’images de pages, nous pourrons obtenir, précise Christopher Kermorvant. Nous sommes en train de rassembler les images de ces documents épars, et c’est déjà une opération complexe. Les cahiers de recensement existent au départ en deux exemplaires, archivés en mairie et à la préfecture. La situation est très variable localement. Dans les meilleurs cas, les documents ont survécu et sont même déjà numérisés, avec une définition satisfaisante. Dans les pires situations, des documents ont été jetés ou ont disparu, par exemple dans des incendies. Aujourd’hui, nous ne savons pas encore quelle proportion nous obtiendrons de ces vingt millions de pages. »
Reste à créer l’outil capable de traiter cette masse de documents bien particuliers. « Nous développons une chaîne de traitement opérationnelle adaptée à ce type de données, indique Christopher Kermorvant. Elle devrait être au point en fin d’année. Nous passerons ensuite à la phase de production, qui devrait s’étendre de 2023 à 2025. La chaîne de traitement que nous mettons en place comporte deux parties. La première, qui repose sur l’apprentissage profond, concerne l’aspect optique : elle détecte les zones de texte et fournit des hypothèses de lecture des caractères, des mots, etc. La seconde partie correspond au traitement linguistique des données. Elle repose essentiellement sur des « transducteurs probabilistes », qui s’appuient sur un certain nombre de bases de données. Dans ce type de document, les données sont organisées selon une grammaire précise. On y cherche donc, dans un certain ordre, un prénom, un patronyme, une profession, une date, un nom de commune, etc. Des bases de données, dont certaines seront alimentées par nos partenaires démographes ou économistes, permettront à notre modèle de lever des ambiguïtés, par exemple sur les prénoms, les noms de commune et même les patronymes. Dans telle région de France, par exemple, un patronyme comme “Dupereg” ne sera pas très plausible, alors que “Duperey” le sera beaucoup plus, sachant qu’un “y” mal formé peut ressembler à un “g”. La partie optique de notre chaîne de traitement, qui détecte les zones de texte et les interprète, repose sur un réseau de neurones comportant une dizaine à une vingtaine de couches, de type convolutionnel ou récurrent. »
 © Archives Départementales du Rhone.
© Archives Départementales du Rhone.
UNE MINE D’INFORMATIONS HISTORIQUES
La partie de cette chaîne de traitement relevant de l’apprentissage profond sera progressivement entraînée sur des corpus aussi représentatifs que possible de la diversité des documents obtenus. Diversité des scripteurs, les agents qui ont rédigé ces documents, et donc diversité des styles d’écriture. « La graphie n’est pas systématiquement soignée et les styles pas toujours homogènes, précise Christopher Kermorvant. Toutes sortes de difficultés d’interprétation se présentent. Des fioritures, par exemple, modifient parfois les lettres initiales, mais aussi finales, par exemple sur la lettre “d”. Bien sûr, les difficultés varient d’une époque à l’autre, l’écriture enseignée à l’école évolue, mais on observe une stabilisation de l’écriture à partir de la fin du XIXème siècle.»
Certaines données, implicites, doivent même être déduites. « Parmi les difficultés rencontrées pour interpréter ces documents, il y a la manière dont certaines informations qui reviennent souvent sont codées par les scripteurs, explique Christopher Kermorvant. Ainsi, dans certaines communes, la plupart des personnes mentionnées dans les cahiers de recensement étant de nationalité française, cette information est donnée en toutes lettres pour le premier individu en haut de page, mais ensuite souvent remplacée par un trait vertical, signifiant que les personnes suivantes sont également de nationalité française. On rencontre le même problème avec l’usage de la mention « idem », ou « id ». L’outil de traitement doit donc être capable d’interpréter ces signes et de retrouver l’information à laquelle ils font référence. »
Le projet produira une base de données renseignant potentiellement sur tous les individus ayant vécu en France entre 1836 et 1936. Elle sera porteuse d’informations qui intéressent les démographes, les économistes ou les sociologues qui pourront les exploiter directement à l’aide d’outils statistiques ou autres. Elle permettra à ces chercheurs d’étudier des évolutions sociales sur le long terme, ce qui améliorera notre compréhension des structures économiques et sociales françaises. Un peu comme le carbone 14, l’intelligence artificielle fait désormais partie de ces outils qui permettent d’explorer notre passé.
Pierre Vandeginste
Image de Une : Recensement de la commune de Saint-Junien-les-Combes, 1911. Document conservé aux Archives départementales de la Haute-Vienne, sous la cote 6 M 214





