

Les données de sciences humaines et sociales
⏱ 7 minComme d’autres, les disciplines des sciences humaines et sociales font désormais face à un déluge de données numériques. Du big data pas forcément rich data, des données qui ne révolutionnent pas non plus ces sciences et qu’il faut, comme par le passé, sélectionner et critiquer sans oublier l’intérêt des analyses qualitatives.
Localiser les déserts médicaux à partir des listes de médecins, hôpitaux et pharmacies, étudier des corpus de textes de lois, un indice de prix à la consommation à partir des prix en ligne, étudier les déplacements de population via le signal des téléphones mobiles, revisiter l’histoire des sciences et des découvertes en suivant les articles pionniers, suivre l’évolution des mots dans les langues à partir des millions de livres numérisés, reconstituer les réseaux de transport locaux à l’époque romaine, analyser les dynamiques commerciales entre l’Europe du Nord et du Sud dans l’Antiquité… Autant d’exemples de valorisations récentes de données de sciences humaines et sociales ou SHS (économie, géographie, sociologie, histoire, sciences politiques, démographie, linguistique, archéologie, philosophie des sciences…) rendues possibles grâce à de nouvelles capacités de traitement.
Plus de données, pas forcément plus de savoir
De fait, l’analyse quantitative n’est pas nouvelle en SHS mais, depuis une quinzaine d’années, l’abondance de données bouleverse les pratiques. Des revues spécialisées ont même vu le jour comme Big Data and Society en 2013. « Mais il n’y a pas toujours des données plus massives à analyser, martèle Etienne Ollion, sociologue à l’université de Strasbourg (UMR SAGE). La question n’est pas tant celle des données massives que celle de la multiplication de données numériques, massives ou pas. Ces données sont dans des formats très divers comme des pages html, des pdf, des photos ou des fichiers MP3… encodées en 0 et 1 pour être lues et analysées par ordinateur. Le vrai changement, c’est qu’on en a beaucoup plus. Et la question est de savoir ce que l’on peut en faire, avec quels outils et quelles méthodes – sujet d’un prochain article de ce dossier, ndlr – et en quoi cela change les compétences nécessaires. »
Quelles sont ces nouvelles données ? Ce sont celles d’internet bien sûr, notamment toutes les « traces » laissées online par les utilisateurs des réseaux sociaux ou de serveurs, mais aussi les données que l’on peut recueillir sur le web, offline (voir figure ci-dessous). Ce sont également toutes les données produites par des organisations (administrations, entreprises, associations), les archives numérisées ou encore les données de capteurs (de smartphones, de carte de transport en commun ou d’objets connectés), etc. « En soi, étudier les traces laissées par des individus ne modifie pas le travail des chercheurs en sciences sociales », rappelle toutefois Claire Lemercier, historienne à Science Po (Centre de sociologie des organisations). Ce qui change est que ces données peuvent être abondantes (parfois à l’échelle d’un pays voire plus), souvent immédiatement disponibles et actualisées. Leur collecte et leur formatage peuvent être facilement automatisés. De quoi multiplier le nombre de bases de données sans pour autant qu’elles ne soient forcément volumineuses et ne nécessitent des ordinateurs puissants.
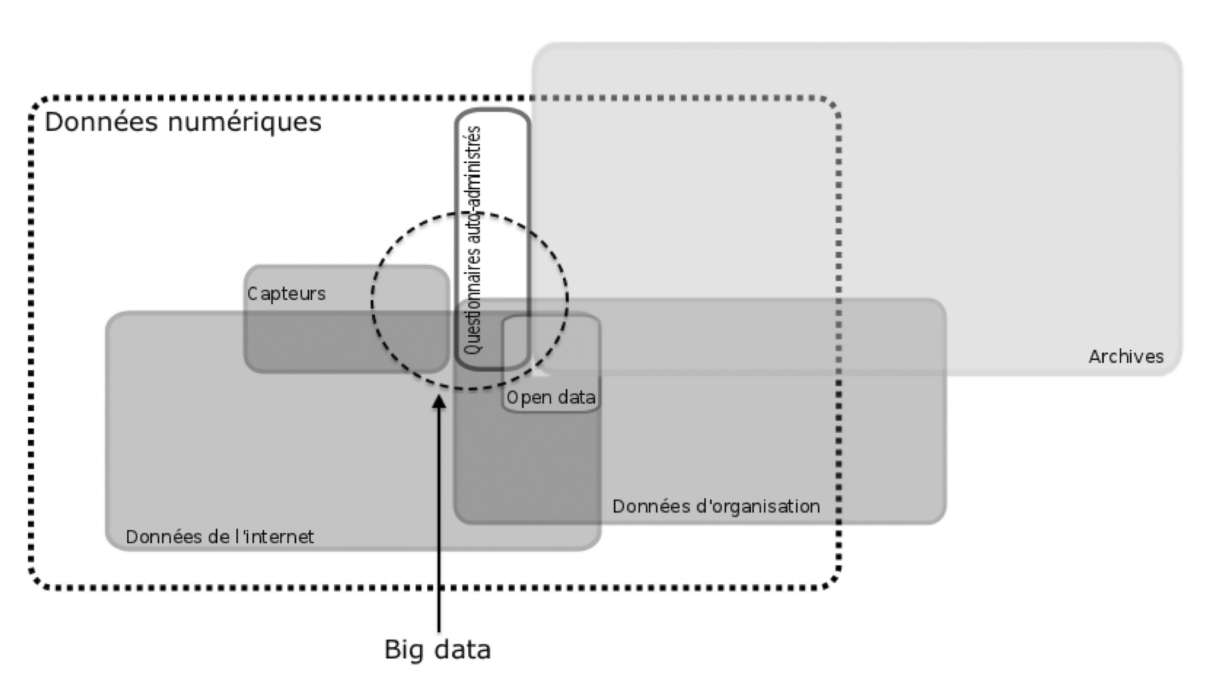
Crédit : E. Ollion, J Boelaert et référence article : https://journals.openedition.org/sociologie/2613] Les auteurs précisent que ce schéma est illustratif et ne fournit pas de représentation à l’échelle de la situation actuelle. Il représente tout au plus l’importance différentielle que prennent certaines sources dans la recherche en sciences sociales, en 2015.
Sélectionner, critiquer
Ces données, en général produites à des fins commerciales, gestionnaires ou administratives (certains parlent de données organiques), ne sont pas forcément utiles aux chercheurs, pas plus fiables ni plus précises que les données d’enquête classique comme les questionnaires. En un mot, big data ne signifie pas rich data. L’erreur commune est de passer ces données numériques à la « moulinette » au lieu de les sélectionner.« Les données des réseaux sociaux, par exemple, peuvent recouvrir une grande variété de significations, précise Fanny Georges, sémiologue à l’université Paris 3 : une même image n’a pas du tout la même fonction si elle est postée sur un forum ou en photo de profil. »
« Il faut continuer à faire ce que les SHS ont toujours fait, poursuit Etienne Ollion : de la critique des sources et un échantillonnage bien construit. Sélectionner les données nécessaires, savoir dans quel contexte elles ont été produites et par qui avant de les faire parler. » Exemple : une plateforme comme Meetic (site de rencontres) fournit les heures de connexion, le signe astrologique des personnes… mais ne dit rien sur leur histoire affective, donnée fondamentale en sociologie du couple. Comme toute donnée, ces nouvelles informations sont partielles, jamais pures, jamais neutres. « Les données ne sont pas la société, confirme Claire Lemercier. La masse ne fait pas disparaitre la question des biais. D’ailleurs, la constitution de la base de données constitue souvent l’étape la plus féconde intellectuellement. »
Le problème de l’accès aux données
« Il ne faut pas se priver de ces immenses bases de données », recommande néanmoins Marc Lelarge, chercheur à Inria qui explore notamment des graphes d’appels (qui est en contact avec qui par téléphone, email, tchat, twitter…) et des graphes sociaux du type Facebook (qui s’est déclaré ami avec qui). « Mais, il faut veiller à questionner les données les plus intéressantes et non pas les plus accessibles, pointe Laurent Beauguitte, géographe de l’UMR Géographie-cités : Ne sommes-nous pas trop dépendants de ce que les plateformes commerciales nous autorisent à utiliser gratuitement, comme Twitter dont une API permet de récupérer facilement de gros volumes de données ? Les données de Youtube, une plateforme a priori bien plus utilisée, ne sont-elles pas plus riches ? »
De fait, propriété intellectuelle et protection des données personnelles (voir notre article sur RGPD) orientent parfois le choix des données. Et les objets même d’étude des sciences sociales ? Pour les données qui ne sont pas en accès libre, la pratique consiste à signer un contrat ou un accord de confidentialité (NDA), une procédure longue et chronophage qui ne se justifie que si les données sont de qualité.
« Certains reprochent à ces données d’être des données dites « organiques », poursuit Etienne Ollion. Pourtant, cela n’est pas nouveau. À part les sociologues qui produisent leurs propres données, beaucoup de chercheurs de SHS tirent profit de données qui n’ont pas été produites à leurs fins, depuis toujours : des économistes travaillent sur les comptes de l’Etat, des linguistes sur la langue, les historiens ou les archéologues sur des traces du passé… »
Du quali et du quanti
Cette abondance de données remet l’analyse quantitative au goût du jour. D’autant plus qu’il est plus facile d’avoir des financements en évoquant données numérique et big data plutôt qu’une analyse de 40 biographies par exemple ! « Mais, dans la plupart des disciplines de SHS, les méthodes quantitatives restent minoritaires », fait remarquer Laurent Beauguitte. Et l’analyse qualitative, à base d’enquêtes, d’observations, d’analyse de textes, d’archives, conserve tout son intérêt. « Les gros volumes de données peuvent révéler des régularités statistiques intéressantes, poursuit le géographe. Mais c’est souvent l’analyse qualitative qui apporte l’explication. » À l’instar du projet Algopol sur l’utilisation de Facebook au cours duquel il a été montré que l’analyse d’une trentaine d’entretiens menés avec des utilisateurs révélait autant que celle d’un gros volume de données. « Il faut faire les deux, avec des méthodes mixtes, conclue-t-il, par exemple en ciblant les entretiens à partir de l’analyse quantitative préalable. »
De nouvelles compétences
Autre conséquence : ces nouvelles données commencent à avoir des incidences sur les compétences requises en SHS, sur une nouvelle forme d’interdisciplinarité fructueuse entre chercheurs de SHS et informaticiens ou statisticiens, sur une nouvelle forme de concurrence aussi, par exemple avec des data journalistes. « Pour certains postes en SHS, il faut désormais savoir écrire des scripts pour collecter automatiquement et nettoyer des données, voire connaitre des méthodes de machine learning, indique Etienne Ollion. Ces nouvelles qualifications sont valorisées. »
« Un enseignement de base sur la collecte, le traitement de données, la critique des sources s’installe progressivement dans les cursus pour permettre aux chercheurs d’interagir en bonne compréhension avec les experts de ces méthodes, ajoute le sociologue. Des formations sont également proposées aux chercheurs. La barrière technique est relativement limitée : quelques jours de cours suffisent pour avoir une formation minimale. » De quoi écrire quelques lignes de code qui permettront à un économiste de nettoyer des bases de données fiscales (supprimer les doublons, repérer les erreurs de codage, harmoniser), à un sociologue urbain de géocoder des commerces dans un quartier, à un historien de transformer des documents scannés en fichiers texte pour analyser leur contenu…
Dans 80 % des cas, les chercheurs en SHS peuvent se débrouiller seuls s’ils s’approprient ces méthodes. Même son de cloche de la part de Claire Lemercier qui a corédigé un ouvrage pour familiariser les chercheurs de sa discipline aux techniques quantitatives (voir ci-dessous). « De nombreux outils sont disponibles sur un simple ordinateur et permettent de renouveler bon nombre d’approches sur toutes les périodes, de l’histoire politique à l’histoire sociale et culturelle », affirme-t-elle, regrettant la course à la complexité, le langage d’initiés et la regrettable impression que les data scientist font parfois appel à eux surtout pour avoir leur données. Dans certains cas, lorsque les collectes sont très ardues, pour des données massives, hétérogènes ou complexes, pour des analyses ou des visualisations spécifiques, il est néanmoins indispensable de travailler avec des informaticiens ou des statisticiens. « Cela impose une acculturation réciproque et une réflexion commune quotidienne, sur le long terme », prévient Fanny Georges qui a conçu une visualisation originale de l’identité numérique (voir l’ article 3 de ce dossier à paraître le 26 juillet).
Des humanités numériques ?
Or beaucoup de chercheurs en SHS sont agacés par les statisticiens et informaticiens, certains recrutés dans des laboratoires de sciences sociales, qui continuent de promettre de révolutionner leur discipline grâce au big data et qui dans le meilleur des cas aboutissent à des résultats d’une banalité confondante. « Avec le recul, ces promesses n’ont pas été tenues, regrette Etienne Ollion. D’ailleurs, le terme même de sciences des données, ou data science, est trompeur. Si cela veut dire une connaissance des données, alors c’est ce que font les chercheurs depuis des décennies. Méfions-nous de ces termes trop flous. » On retrouve ici des traces de l’opposition entre « sciences dures » et humanités que le terme « humanités numériques » ne contribue pas à apaiser. « Comme si les sciences sociales n’avaient pas réfléchi depuis un siècle à la mise en données, à la quantification, la modélisation, la visualisation souvent avec des informaticiens, des mathématiciens, des physiciens… », regrette Claire Lemercier.
Isabelle Bellin
Pour en savoir plus :
- Au-delà des big data : Les sciences sociales et la multiplication des données numériques, E. Ollion et Julien Boelaert, Sociologie, N°3, vol.6, 2015 : https://journals.openedition.org/sociologie/2613
- Le site Data Sciences Sociales : https://data.hypotheses.org/
- LemercierClaire, ZalcClaire, Méthodes quantitatives pour l’historien. La Découverte, « Repères », 2008, 128 pages : https://www.cairn.info/methodes-quantitatives-pour-l-historien–9782707153401.htm
- BIDART, Claire et KORNIG, Cathel. Facebook pour quels liens? Les relations des quadragénaires sur Facebook. Sociologie, 2017, no 1, vol. 8. https://www.cairn.info/resume.php?ID_ARTICLE=SOCIO_081_0083





