

Le machine learning en sciences humaines et sociales
⏱ 4 minL’apprentissage automatique (machine learning) est une des méthodes d’analyse quantitative susceptible d’être utilisée en sciences humaines et sociales (SHS). Pour quels types de données est-il adapté ? Qu’apporte-t-il ? Qui peut utiliser ces techniques ?
« Après des hauts et des bas depuis les années 1950, le machine learning connaît un regain d’attention depuis quelques années. Les SHS commencent à s’y intéresser à mesure qu’augmentent les données numériques disponibles pour l’analyse », résume Etienne Ollion, sociologue à l’université de Strasbourg (UMR SAGE) (voir article 1 de ce dossier, « les données de sciences humaines et sociales« ). Le chercheur, qui enseigne les sciences sociales computationnelles en France et aux Etats-Unis, observe les mêmes débats dans l’Hexagone et Outre-Atlantique. « Il y a beaucoup d’intérêt, mais aussi des espoirs démesurés ; il ne faut pas promettre monts et merveilles : le machine learning est utile mais seulement dans certains cas. C’est un peu la même histoire que pour les big data voilà dix ans : certains avaient promis une révolution des SHS. Les résultats n’ont pas été à la hauteur des promesses mirifiques (voir article 3 de ce dossier, »L’analyse quantitative des données de sciences humaines et sociales« ).»
C’est d’autant plus délicat qu’en ce qui concerne le machine learning, peu de chercheurs en SHS maitrisent ces méthodes algorithmiques. « Nous sommes trop peu nombreux à pouvoir faire des allers-retours entre les notions des sciences humaines et celles des statistiques, théorie des graphes ou, plus récemment, de machine learning », confirme Antoine Mazières post doctorant au Centre Marc Bloch (CMB) à Berlin au sein d’une des principales équipes européennes de sciences sociales computationnelles. Chercheur en science politique, il a découvert la science des données lors de sa thèse sur les différentes communautés algorithmiques de machine learning. « Les cursus comme Science Po commencent à intégrer un enseignement de statistiques mais plutôt traditionnelles, note-t-il. Or tout le spectre de méthodes d’analyse de données est utile selon les données et les questions posées, d’algos très simples jusqu’aux réseaux de neurones, en passant par les régressions linéaires. »
Pour quelles données ?
Qu’apporte le machine learning aux SHS ? « Un nouveau matériel pour étudier des problèmes pour lesquels nous n’avions pas de solution, répond Antoine Mazières qui a, par exemple, étudié la discrimination ethnique à partir de l’estimation de l’origine des personnes selon leur nom de famille dans différents contextes (bac, assemblée nationale, mairies, chercheurs CNRS, polytechniciens…) : « Les données sur l’origine ethnique étant proscrites en France, l’étude des patronymes m’a permis de contourner le problème. » Le chercheur souligne néanmoins que les données SHS sont, en général, peu adaptées au machine learning : « Ce sont souvent des données abstraites et symboliques comme des données de questionnaires, dont le sens est parfois implicite, auxquelles il faut appliquer un traitement de texte alors que le machine learning excelle avec des données fondamentales comme des pixels ou des ondes sonores. »
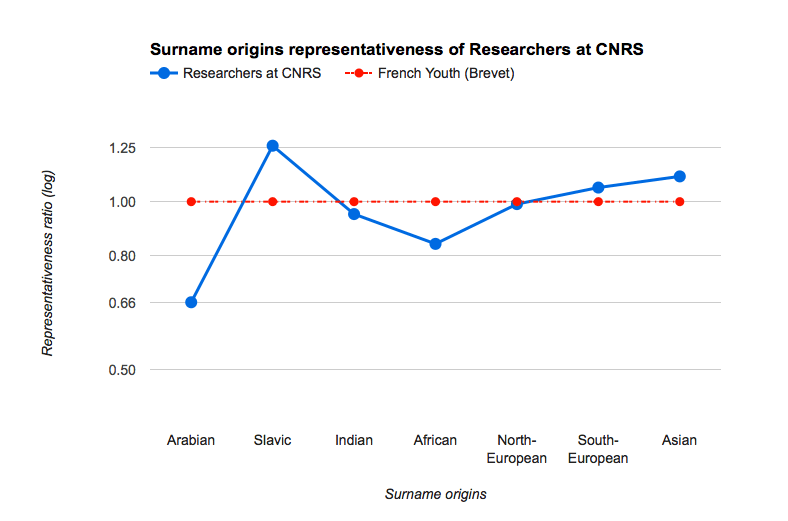
Supplemental materials to the article published in Bulletin of Sociological Methodology (July 2018)
by Antoine Mazières et Camille Roth.
« Le machine learning, en particulier l’apprentissage supervisé, peut être particulièrement efficace lorsque le volume de données est important même si ce n’est pas toujours le cas en SHS, note cependant Etienne Ollion. On peut alors s’affranchir de bon nombre d’hypothèses relatives à la structure des données (comme la linéarité), nécessaires avec la plupart des méthodes classiques plus adaptées à des échantillons ne dépassant pas quelques milliers. » Dans une recherche qui compare régression linéaire et machine learning supervisé (sur les déterminants du salaire en Suède), il montre que les techniques de learning fonctionnent bien, mais à partir de 10 000 observations (1). Avant 3000, la régression linéaire, inventée au siècle dernier, est bien plus efficace. Pour autant, machine learning n’est pas forcément synonyme de big data, en particulier en matière d’apprentissage non supervisé, de plus en plus utilisé en SHS depuis 5 ans.
Dans quels buts ?
Le machine learning est utile aux SHS sous forme d’apprentissage supervisé pour la régression et la classification, et sous forme d’apprentissage non supervisé pour la réduction de dimensionnalité pour construire une représentation synthétique et pour le clustering pour identifier des groupes.
Mais comme dans toutes leurs applications, le manque d’interprétabilité des techniques d’apprentissage pose question, notamment en ce qui concerne le deep learning, à base de réseaux de neurones. « Or les sciences, sociales ou non, se sont en partie construites sur la recherche de la causalité, rappelle Etienne Ollion. Cela handicape clairement ces technologies dont l’objectif premier est prédictif. Elles auront bien du mal à se remplacer les méthodes classiques d’analyse quantitative (statistiques descriptives, statistiques inférentiellesLa statistique inférentielle, que l’on distingue traditionnellement de la statistique descriptive, consiste à inférer d’un échantillon aléatoire des propriétés de la population étudiée, essentiellement sur le mode de tests d’hypothèses. , analyses de réseaux) dans ce domaine. Mais leurs puissantes capacités d’extraction d’information peuvent être utilisées pour confirmer ou infirmer les méthodes plus classiques. Quant au machine learning non supervisé, ses capacités descriptives peuvent être mises à profit, que ce soit à des fins d’analyse exploratoire ou en tant que tel. Elles pourraient favoriser le développement d’une description robuste, armée de nombreuses observations, entre statistique inférentielle et traitements qualitatifs plus classiques.»
Mais il ne faut pas sous-estimer la barrière mathématique. « On peut apprendre à utiliser les logiciels de machine learning en quelques jours, ajoute-t-il, mais aller plus loin suppose un gros travail personnel. » L’interdisciplinarité serait-elle la meilleure solution pour tirer parti au mieux de ces techniques complexes ? « Les points de vue changent, note Antoine Mazières. Les chercheurs en SHS considèrent moins les statisticiens comme des ingénieurs devant adhérer à leur propre vision. Et la façon de poser les problèmes évolue aussi : au lieu de se poser une question et de chercher des données pour y répondre, on commence à profiter du flot d’idées, de données, sans a priori. L’interdisciplinarité bouleverse les codes et c’est une bonne chose. »
Attention à la formulation
Il souligne aussi qu’il ne faut pas minimiser les quiproquos épistémologiques : « Prenons la discrimination : c’est un effet pervers de la société, à combattre pour un sociologue alors que c’est un gage de qualité quand on parle d’un algorithme ! Il faut reconnaitre qu’il est difficile, pour un chercheur SHS, de s’y retrouver dans ce vocabulaire, presque tribal… » Inversement, il fait remarquer que la notion de « communautés », très utilisée en sociologie, a probablement favorisé l’usage de la technique de détection de communautés dans les graphes, qui se développe depuis une dizaine d’années. Pour une fois, le sens était commun ! Comme quoi, il faut commencer par se parler.
Isabelle Bellin
Pour en savoir plus :
(1) Julien Boelaert, Etienne Ollion, « The Great Regression : Machine Learning, Econometrics, and the Future of Quantitative Social Sciences », à paraître in Revue Française de Sociologie, 59-3, 2018. En preprint sur HAL.





