

Comment la voiture autonome apprend à conduire, pas à pas…
⏱ 6 minAu cœur de la voiture autonome, on trouve les mêmes algorithmes d’apprentissage automatique que ceux utilisés pour la classification des images ou la reconnaissance de la parole. Mais avant de pouvoir embarquer dans le véhicule, ces algos font l’objet de tests stricts. Sécurité oblige.
Certes, la voiture totalement autonome n’existe pas encore. Mais les véhicules n’ont cessé de gagner en autonomie ces dernières années. La raison principale ? Les progrès fulgurants accomplis en matière d’intelligence artificielle, en particulier par certains algorithmes, dits de machine learning. Ces méthodes d’apprentissage automatique, basées sur l’exemple, sont notamment utilisées pour la reconnaissance des visages sur les photos. Désormais, elles se retrouvent au cœur du fonctionnement des voitures sans pilote.
Détecter, identifier, classer…
« Ces algos permettent de donner un sens aux données issues de capteurs en fournissant une représentation détaillée de l’environnement autour de la voiture », explique Fabien Moutarde, du centre de robotique de MINES ParisTech. À partir des images des caméras, ils sont chargés de détecter tous les obstacles et de les classer par catégories (piétons, vélos, motos, bus, camions…) ; d’identifier les panneaux de signalisation et de lire leur contenu ; de savoir quand un feu passe au vert ou au rouge ; de faire la distinction entre la route et le bas-côté ; de repérer les différentes configurations de la route (intersections, ronds-points…) ou encore les différents types de marquages au sol. Idem pour les données des radars et des lidars, elles aussi interprétées par du machine learning.
Cette connaissance de l’environnement vient ensuite alimenter d’autres algorithmes déterministes cette fois, basés sur des règles. Sachant où se trouvent les obstacles et leur type, et prédisant leur positions futures, ces algos de planification décident de la manœuvre la plus sûre à exécuter, et cela dans le respect du Code de la route.
Mais avant de pouvoir monter à bord d’une voiture, les algos d’apprentissage doivent d’abord faire la preuve de leur efficacité en laboratoire. Dans un premier temps, on les entraîne sur un vaste jeu de données collectées par les capteurs dans de multiples conditions de circulation : sur autoroute, nationale, route rurale, périphérique, en ville, sous différentes conditions météo ou avec plus ou moins de trafic, etc. Sur des millions d’images réunissant plusieurs milliers de catégories d’objets, les algos apprennent ainsi à les détecter et à les classifier. Cet apprentissage se fait de façon supervisée : sur chaque image, on a indiqué au préalable où se trouve chaque objet et de quel type il s’agit – ce qu’on appelle la labellisation.
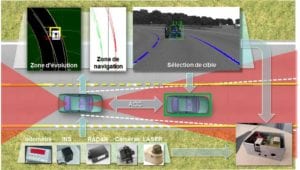
Caméras, radars, lidar, GPS : les multiples « yeux » de la voiture autonome
pour se repérer dans son environnement et identifier les obstacles.
Être entrainés pour apprendre
Dans cet exercice d’entraînement des algos, la diversité des données est la clé. « La base de données doit être la plus représentative de tous les cas de figure possibles, sans quoi on passera forcément à côté d’une détection une fois la voiture sur la route. Par exemple, pour les piétons, il est important d’avoir une large palette de couleurs de vêtements, de corpulence ou encore d’orientation (face, profil, etc.). Il faut donc garantir cette diversité au moment de constituer sa base de données », précise Fabien Moutarde.
Une précaution d’autant plus importante que d’un pays à un autre, la voiture devra faire face à des situations nouvelles, comme des panneaux de signalisation complètement différents. Les algorithmes doivent donc être adaptés à un pays donné ou à une géographie donnée.
Une fois l’entraînement terminé et les algorithmes jugés suffisamment performants dans leurs détections – on vise un taux de réussite supérieur à 90 % -, il n’est toujours pas question de les embarquer dans la voiture. Ils doivent d’abord passer l’étape de la validation. Cette fois, les algos sont testés sur des données plus nombreuses encore et différentes de celles sur lesquelles ils ont été entraînés. Il s’agit ainsi de vérifier leur capacité à extrapoler dans des situations nouvelles et à pointer du doigt des cas dans lesquels ils peuvent mis en difficulté.
Rejouer la scène encore et encore
Le nombre de scénarios à valider est colossal : les spécialistes estiment qu’à terme les tests devront porter sur l’équivalent de 10 milliards de kilomètres parcourus ! Autant de données qu’il faudra non seulement collecter mais aussi labelliser. Devant l’ampleur de la tâche, certains privilégient une autre approche : la simulation. « L’avantage de la simulation est qu’il est possible de reproduire dans un environnement contrôlé toutes les situations dangereuses et critiques, même celles qui sont rares dans la réalité, comme un enfant qui traverse la route au dernier moment. De plus, la simulation permet la répétabilité des scénarios. On peut ainsi rejouer autant de fois qu’on veut une scène routière en modifiant les paramètres à chaque fois : les conditions climatiques, l’état des capteurs, etc. », note Dominique Gruyer, de l’Institut français des sciences et technologies des transports, de l’aménagement et des réseaux (Ifsttar).
Reste que les simulateurs ne peuvent pas tout faire. Et même leurs partisans estiment qu’on n’échappera pas de toute façon à une validation finale des algorithmes, certes sur beaucoup moins de kilomètres, mais en conditions réelles. « Difficile de battre la réalité pour savoir si l’analyse des algos est juste. Des détails aussi fins que l’ombre projetée d’un objet sur le sol ou le reflet d’un objet par un autre, très difficiles à simuler, peuvent parfois réussir à tromper la machine », estime Fabien Moutarde. Pour le chercheur, la collecte massive de données sera primordiale pour tester et améliorer en permanence les algos et sur ce point, les millions de kilomètres déjà enregistrés par les voitures de Google et de Tesla leur donnent aujourd’hui un avantage décisif.
Valider les algos
Que ce soit sur simulateur, en conditions réelles ou les deux à la fois, une chose est sûre : la validation des algorithmes devra être bien mieux encadrée qu’elle ne l’est aujourd’hui. Actuellement en effet, il n’y a pas de système d’évaluation standard, les constructeurs définissant leurs propres critères. À l’avenir, tout comme il existe des normes de pollution pour les véhicules, il faudra pouvoir comparer de manière quantifiée la qualité des algos des différents constructeurs grâce à des jeux de données standardisés.
Là en tout cas où tout le monde se rejoint, c’est sur l’objectif à atteindre : faire baisser drastiquement la mortalité sur les routes. Aujourd’hui, en France par exemple, une dizaine de personnes trouvent la mort pour chaque milliard de kilomètres parcourus, du fait d’une erreur humaine dans la très grande majorité des cas. Une fois les voitures sans conducteur mises en circulation, on pense pouvoir diviser ce chiffre au moins par dix.
Mais comment arriver à cet objectif (un mort pour un milliard de km soit une probabilité de 10-9) sachant que même les meilleures méthodes de machine learning, les algorithmes d’apprentissage profond (deep learning) et leur fameux réseaux de neurones – les plus utilisés aujourd’hui dans la voiture autonome –, se trompent dans leur interprétation dans 1 % des cas (donc une erreur de 10-2) ?
Fusionner les algos et les données
La solution viendra de l’utilisation combinée d’algos qui fonctionneront simultanément dans la voiture. De la même façon que les capteurs embarqués, de nature différente, donneront des informations complémentaires ou redondantes (lire article 1: « Voiture autonome : un déluge de données à interpréter »), les algos aussi devront présenter une certaine diversité pour augmenter la fiabilité. « L’idée est d’utiliser en parallèle une approche deep learning, et une ou plusieurs autres méthodes de machine learning, pour que chacune donne son interprétation de l’environnement. De cette façon, les éventuelles erreurs des divers algos ne concerneront pas les mêmes parties de la scène », note Fabien Moutarde. On peut par exemple utiliser une première méthode pour détecter les obstacles et une seconde pour détecter l’espace libre de navigation autour de la voiture : à elles deux, elles fourniront une information plus robuste sur la trajectoire à prendre.
Mais cela ne sera pas suffisant : pour faire diminuer plus encore le taux d’erreur des algorithmes d’apprentissage, il faudra fusionner les données fournies par les différents capteurs.« La fusion consiste à mettre en commun et à recouper les informations provenant de ces différentes sources pour enrichir la représentation de l’environnement et améliorer la fiabilité des données. Cela permet notamment d’augmenter la certitude sur la présence ou non d’un obstacle et d’être plus précis sur sa position, sa vitesse, son cap…», explique Dominique Gruyer.
Aujourd’hui, deux stratégies sont envisagées pour fusionner les données. Une première consiste à combiner tardivement toutes les pistes de détection des différents capteurs pour évaluer lesquelles sont les plus plausibles. Une seconde vise à recouper les informations plus en amont. Par exemple, si le lidar identifie un obstacle à un certain endroit, on regarde plus finement à cet endroit l’image fournie par les caméras pour confirmer ou non cet objet. Ou inversement. Cette dernière approche, encore à l’état de recherche, semble plus faire l’unanimité car elle offre davantage de flexibilité sur la manière de détecter les objets.
Gérer l’imprévisible
Mais à supposer qu’après toutes ces étapes, on arrive à créer une voiture autonome suffisamment sûre, il resterait certaines situations auxquelles elle ne pourrait pas faire face. Prenez par exemple la place de l’Etoile à Paris aux heures de pointe. Quand bien même une voiture sans pilote parviendrait parfaitement à décrypter le mouvement des autres voitures conduites par des humains, il y a fort à parier qu’à un moment donné elle n’arriverait plus du tout à avancer, les algorithmes de planification lui imposant des marges de sécurité trop grandes pour se frayer un chemin dans tout ce trafic.
C’est pour éviter ce genre de scénario que les chercheurs tentent actuellement de développer d’autres algorithmes d’apprentissage, dits par renforcement, auxquels on apprend non pas à reconnaître des objets mais à faire le bon choix en fonction de ce qui passe autour de la voiture. L’apprentissage se déroule là dans un simulateur : en multipliant les situations de conduite et en répétant une même situation un très grand nombre de fois, l’algo parvient à trouver la meilleure façon de se comporter dans tel scénario. Une fois sur la route, la voiture déduira ainsi directement des données envoyées par ses capteurs quel angle au volant et quel freinage ou accélération il lui faudra appliquer. La méthode n’en est encore qu’à ses balbutiements mais elle promet de rendre les voitures intelligentes totalement autonomes. Patience !
Julien Bourdet





